From Basic Recall to Agentic RAG — Why Memory Defines AI Capability
Modern AI systems are no longer just generators of text—they are reasoners, decision-makers, and increasingly autonomous agents.
What separates a smart model from a capable agent is one foundational capability:
Memory & Retrieval.
Whether answering questions, executing workflows, or reasoning across long projects, an agent must be able to:
- Store past interactions
- Recall knowledge
- Retrieve documents
- Combine memory with reasoning
- Improve decisions over time
This is where RAG (Retrieval-Augmented Generation) and its next evolution, Agentic RAG, come in.
What Is Memory & Retrieval in Agentic AI?
Memory & retrieval refers to the systems that allow an AI agent to store, access, and reuse information over time.
Traditional LLMs only use short-term context windows.
Agentic AI systems need something far more powerful:
- Short-term context
- Long-term vector memory
- External knowledge retrieval (RAG)
- Episodic memory
- Semantic memory
- Tool-based retrieval (search, APIs, databases)
These memory layers allow agents to perform multi-step reasoning, track state, and recall previous instructions—just like humans.
How RAG Works: The Core Retrieval Pipeline
RAG (“Retrieval-Augmented Generation”) enhances LLMs by giving them access to external knowledge.
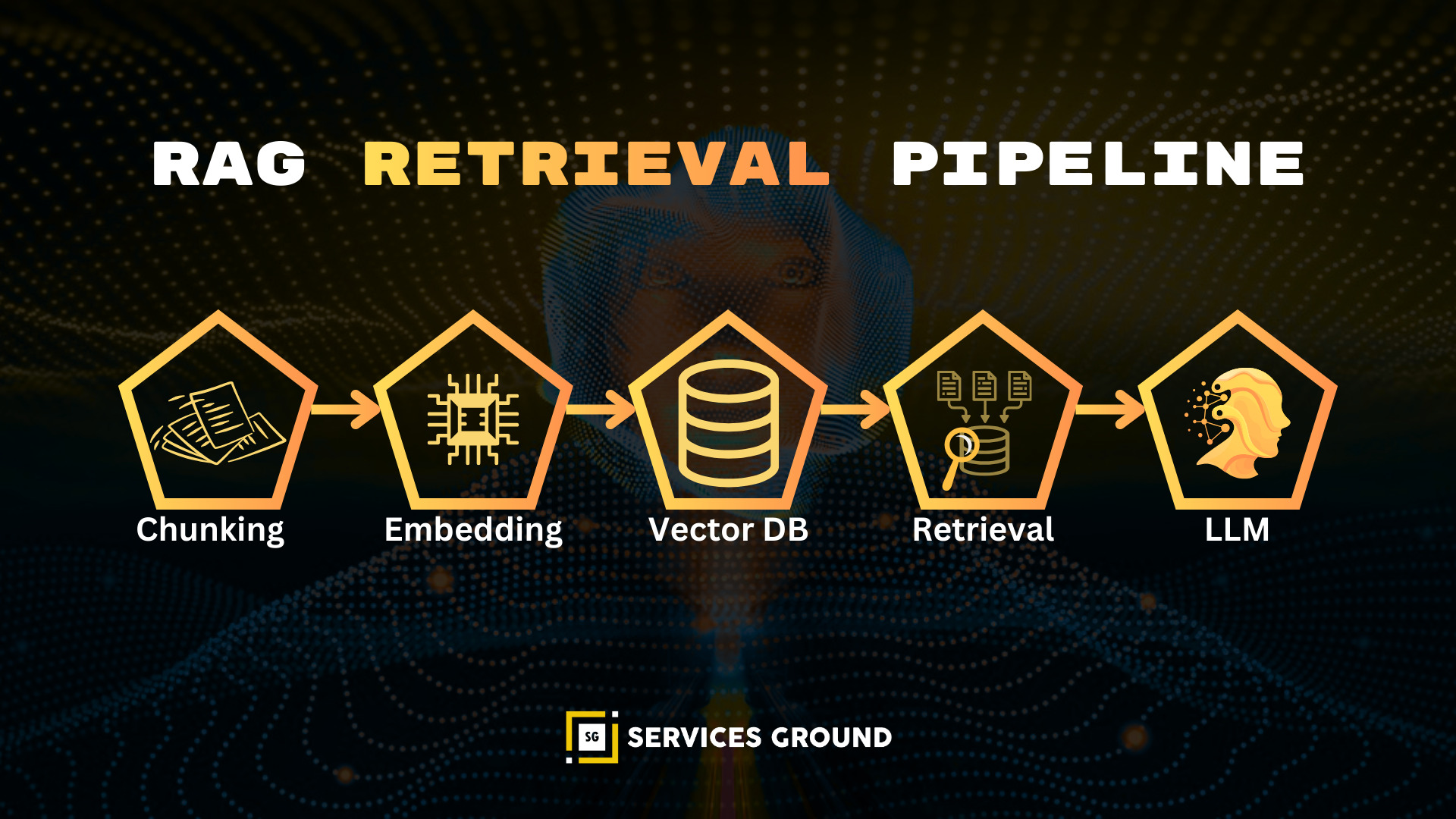
RAG Pipeline Overview
- Chunk documents
- Convert chunks into vector embeddings
- Store embeddings in a vector database (FAISS, Pinecone, Milvus, Weaviate)
- Retrieve relevant chunks based on similarity search
- Feed retrieved knowledge back into the LLM
- Generate an accurate, grounded answer
This solves LLM limitations:
| Problem | RAG Solution |
| Hallucination | Retrieve grounded facts |
| Knowledge cutoff | Access external info |
| Limited context window | Pull only relevant chunks |
| Inconsistent reasoning | Add structured context |
Chunking & Embedding: How Knowledge Is Prepared
Chunking splits documents into semantically meaningful pieces.
Embedding converts each chunk into a vector that captures meaning.
Common embedding models:
- OpenAI text-embedding-3-large
- Gemini embedding models
- Cohere Embed v3
- Nomic Embed
Chunk size: 200–800 tokens is the sweet spot.
Retrieval: How Agents Find Relevant Knowledge
Retrieval methods include:
- Similarity Search
- Hybrid Search (vector + keyword)
- Re-ranking (ColBERT-v2, BERT-based re-rankers)
- Graph-based retrieval (GraphRAG)
Re-ranking improves relevance by scoring retrieved chunks before sending them to the LLM.
Types of Memory in Agentic AI
Agents need multiple memory layers.
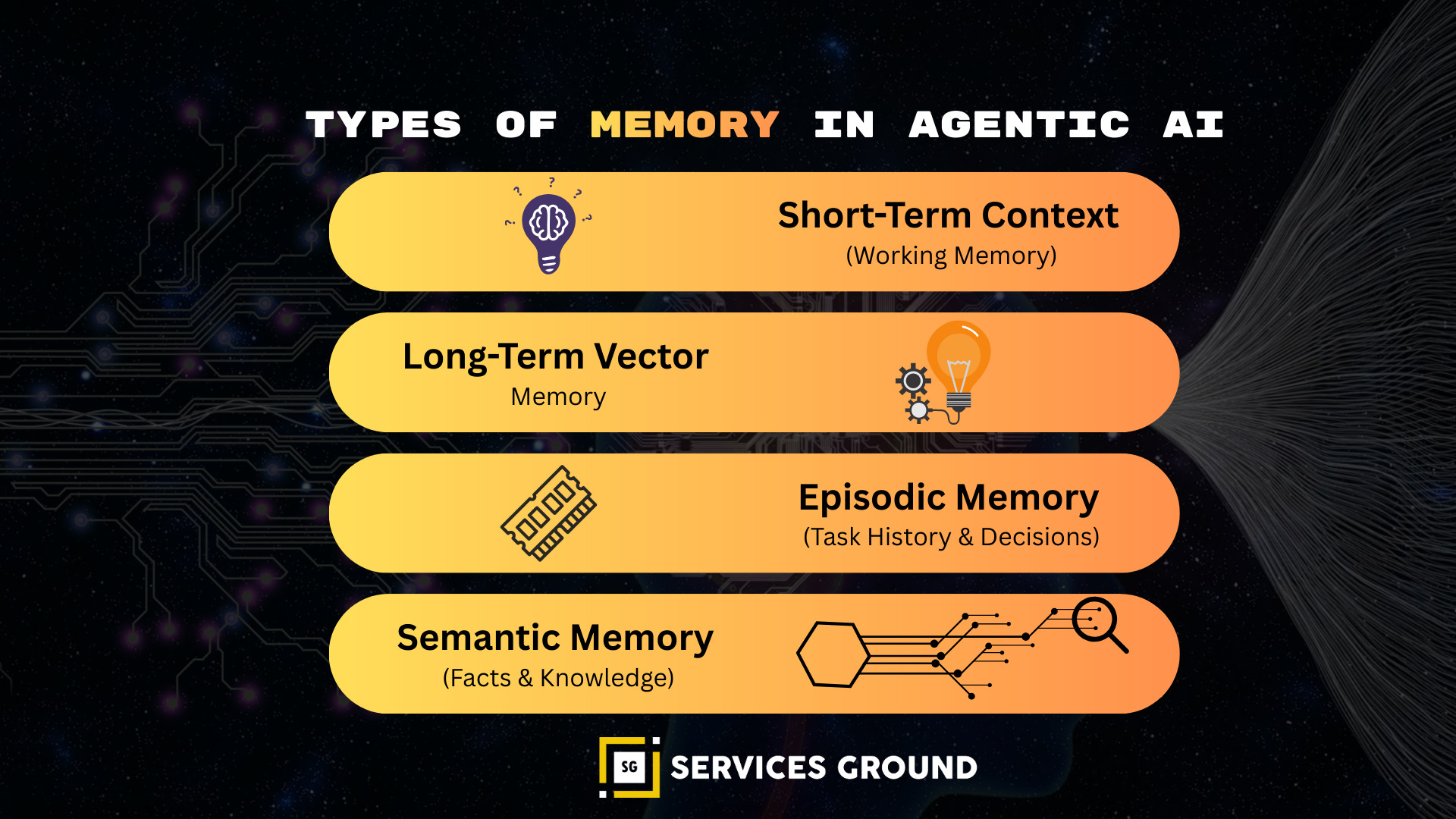
Short-Term Context (Ephemeral Memory)
Stored inside the model’s context window (e.g., 32k–200k tokens).
Used for active conversations and immediate tasks.
Long-Term Vector Memory
Stored in vector databases.
Used for knowledge recall across sessions.
Episodic Memory
Stores key events, decisions, or failures.
Useful for autonomous workflows and multi-day tasks.
Semantic Memory
Stores general world knowledge or domain-specific expertise.
Tool Memory
Agents retrieve knowledge from tools:
- Web search
- APIs
- SQL queries
- Cloud file systems
Enterprise documents
Agentic RAG: The Next Evolution of Retrieval Systems
Traditional RAG retrieves documents only when asked.
Agentic RAG retrieves knowledge proactively, based on agent intent, goals, and intermediate reasoning.
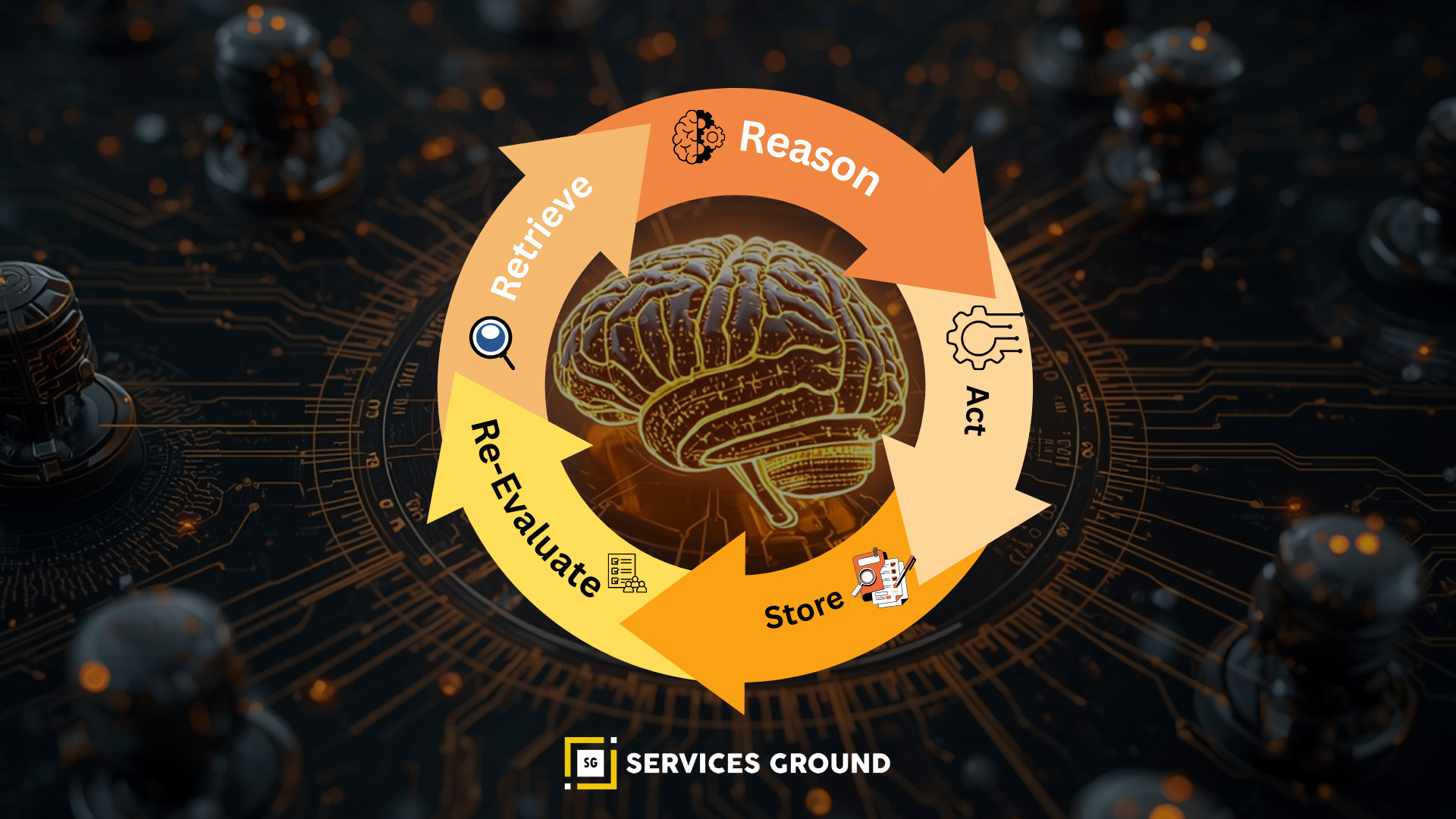
What Agentic RAG Adds
- Agents identify missing knowledge
- Agents perform recursive retrieval
- Agents refine and verify answers
- Agents write structured queries
- Agents cross-check facts with multiple retrieval strategies
- Agents use tools automatically (search, web, APIs)
Agentic RAG Loop
- Reason → determine what info is missing
- Retrieve → query vector DB + web + APIs
- Re-evaluate → check if retrieved info answers the query
- Act → generate final output or take next step
- Store → update memory
This is retrieval + reasoning + autonomy.
When to Use Agentic RAG vs. Standard RAG
| Use Case | Best Choice |
| Simple Q&A | Standard RAG |
| Knowledge-heavy analysis | Agentic RAG |
| Multi-step research | Agentic RAG |
| Enterprise systems | Agentic RAG + structured outputs |
| Search tools | Hybrid RAG |
| Large KB | GraphRAG |
Retrieval Architectures in Modern AI Systems
Standard RAG Architecture
LLM → Retriever → Vector DB → Context → Answer
Agentic RAG Architecture
LLM (reasoning agent)
↓
Query Planner
↓
Retriever (vector + keyword + web + APIs)
↓
Re-ranking
↓
Summarizer
↓
Memory Store
↓
Final Decision
GraphRAG Architecture
Used by Microsoft for deep analysis.
Builds a knowledge graph from documents:
- Nodes = entities
- Edges = semantic relationships
Retrieval becomes contextual and relational
Practical Tools & Frameworks for RAG Systems
Vector Databases
- FAISS (open-source, fast, local)
- Pinecone (cloud, scalable, high recall)
- Milvus (distributed, high-volume)
- Weaviate (hybrid search + modules)
Qdrant (lightweight, production-ready)
Frameworks with RAG Built-In
- LangChain
- LlamaIndex
- Haystack
- Semantic Kernel
Retrieval APIs
- Bing Search
- Tavily AI Search
Brave Search API
Real-World Use Cases of Agentic RAG
- AI research assistants: Recursive retrieval + multi-document reasoning.
- Customer support agents: Retrieve policies + logs + past interactions.
- Coding agents: Retrieve codebase, documentation, and past commits.
- Enterprise knowledge bots: Retrieve documents across SharePoint, PDF, Notion, Drive, Confluence.
- Financial & legal compliance: Retrieve regulations + historical cases.
Best Practices for Memory & Retrieval Systems
- Use hybrid retrieval (vector + keyword).
- Use re-ranking models for high precision.
- Store structured memory (JSON).
- Keep episodic memory short to avoid noise.
- Use GraphRAG for complex domains.
- Use memory pruning to remove irrelevant info.
- Enable output verification & evidence sourcing.
Always log retrieval queries for debugging.
Frequently Asked Questions
RAG stands for Retrieval-Augmented Generation—LLMs retrieve external knowledge to produce accurate answers.
A retrieval system where agents reason, retrieve, validate, and refine results autonomously.
FAISS for local, Pinecone for scalable cloud deployments, Milvus for massive datasets.
Memory stores past info; retrieval finds relevant info from stored knowledge.
It reduces them significantly by grounding answers in factual context.