



Modern AI systems increasingly rely on retrieval, memory, and knowledge grounding rather than generating text in isolation. In Retrieval-Augmented Generation (RAG) and agentic AI systems, the model must locate the most relevant information, combine it with reasoning, and produce answers grounded in accurate context.
That requires a core component: a vector database.
Vector databases store embeddings of numerical representations of text, images, or other content and retrieve semantically similar information based on distance in high-dimensional space. Without fast, accurate retrieval, a RAG system cannot function reliably.
As workloads grow from thousands to millions or billions of documents, traditional keyword search and relational databases fall short. Vector databases fill this gap by enabling semantic retrieval, high-throughput indexing, hybrid search, and distributed memory for agents that must operate over long time horizons.
This guide provides an expert, end-to-end look at vector databases for RAG and agentic AI. It explains how they work, compares leading options Pinecone, Weaviate, FAISS, Qdrant, and Milvus and provides design patterns, failure modes, and decision frameworks grounded in real engineering trade-offs.
What Is a Vector Database?
A vector database is a specialized system for storing high-dimensional embeddings and retrieving the closest matches using similarity search algorithms. Unlike keyword search, which depends on lexical overlap, vector search operates on meaning.
From an engineering perspective, a vector database is optimized for:
- Storage of high-dimensional numerical vectors
- Approximate nearest neighbor (ANN) search
- Specialized index structures (HNSW, IVF, PQ, DiskANN, etc.)
- Low-latency retrieval at scale
- Horizontal and vertical scaling
- Metadata filtering and hybrid search (vector similarity + filters)
- Durability, replication, and consistency guarantees
Vector databases are now foundational for:
- RAG and agentic AI
- Semantic search and question answering
- Recommendation systems
- Long-term agent memory
- Multimodal retrieval (text, images, code, logs, events)
Why Vector Databases Are Crucial for RAG and Agentic AI
1. Retrieval Quality Controls Answer Quality
In RAG, the LLM reasons over retrieved context. If the right documents do not show up, the model will hallucinate or produce incomplete answers even if the LLM itself is very strong. Retrieval quality is often the real bottleneck, not model quality.
2. Latency Controls User & Agent Experience
RAG and agentic systems often perform multiple retrievals per user query or reasoning step. Each retrieval must typically complete within 50–200 ms to keep overall response times acceptable. Slow retrieval cascades into sluggish agents and broken multi-step workflows.
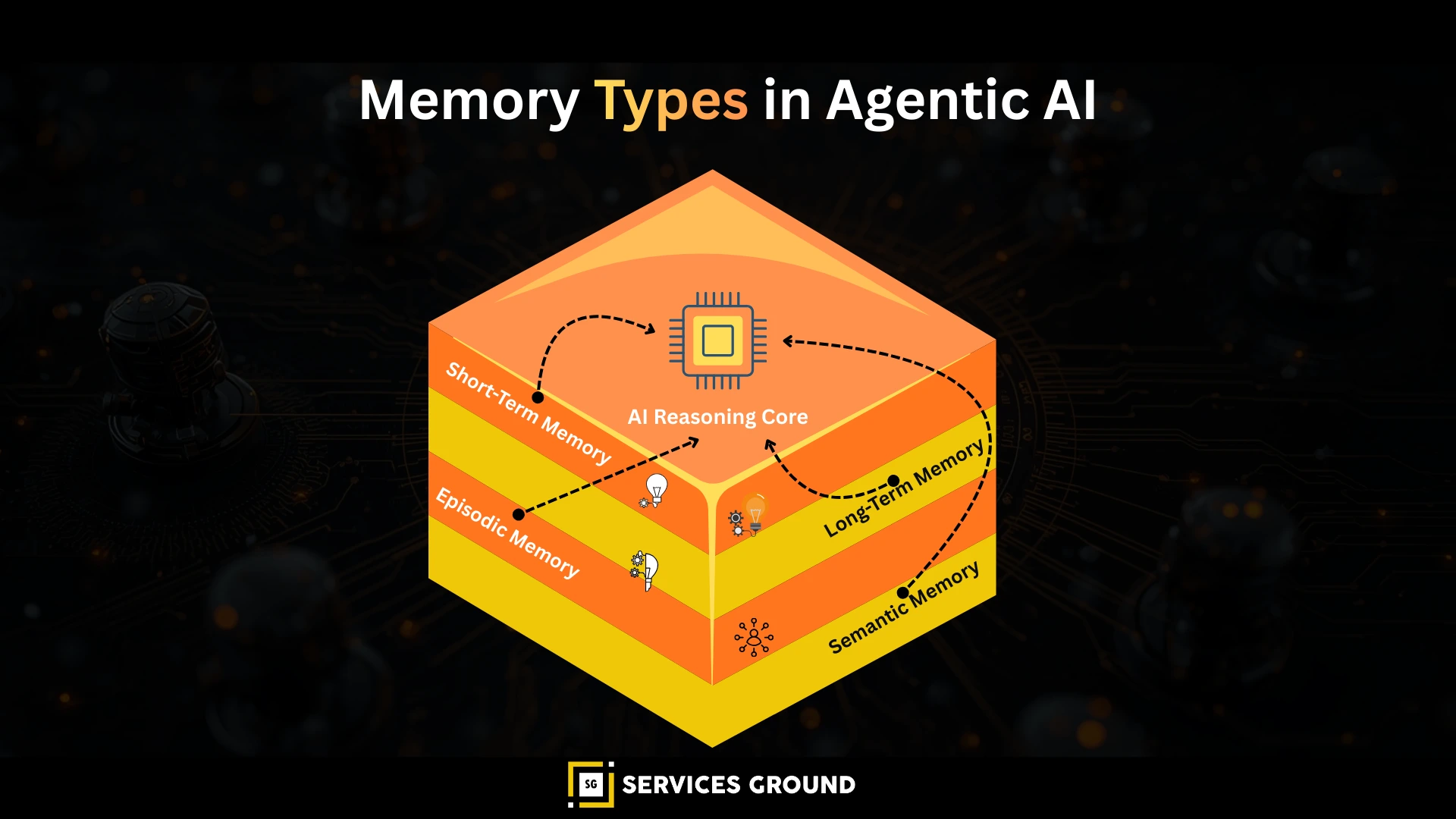
3. Vector Databases Provide Long-Term Memory
LLMs are stateless. They do not remember previous sessions or decisions unless explicitly provided with that context. Vector databases act as the external memory layer where agents can store and recall:
- Past interactions
- Decisions and outcomes
- Internal reflections
- Domain knowledge and documents
4. Scalability for Enterprise Use
At enterprise scale, knowledge bases routinely reach tens or hundreds of millions of documents. Only purpose-built vector databases can maintain high recall and acceptable latency over these volumes without prohibitive cost.
5. Multi-Step and Multi-Agent Reasoning
Agentic systems repeatedly call the vector store during:
- Planning and re-planning
- Tool selection and evaluation
- Episodic memory lookup
- Cross-agent coordination
Efficient vector databases become the backbone of these agent loops.
Core Technical Concepts Behind Vector Databases
Understanding how different vector databases behave starts with the underlying concepts that govern embedding storage, indexing, and retrieval.
Embeddings: The Foundation of Semantic Retrieval
Embeddings map inputs (text, images, code, etc.) into high-dimensional vectors. Examples:
- Text → 768-dimensional BERT embeddings
- Text/code → 1,536+ dimensional OpenAI embeddings
- Images → 1,024+ dimensional CLIP embeddings
- Multimodal inputs → 2,048+ dimensional vectors
Semantically similar inputs end up close to each other in vector space. For RAG and agentic AI, retrieval quality is a function of:
- Embedding model selection
- Index quality and configuration
- Query strategy (query embedding, filters, reranking)
A high-quality vector database cannot compensate for fundamentally poor embeddings.
Similarity Metrics: How Closeness Is Computed
Vector databases typically support one or more similarity metrics:
- Cosine similarity: Measures the angle between vectors. Good when magnitude is irrelevant.
- Dot product: Magnitude influences similarity. Often used with normalized vectors.
- Euclidean (L2) distance: Measures straight-line distance between vectors. Effective when embeddings form tight clusters.
Choosing a metric misaligned with the embedding model’s training can silently degrade recall.
Index Structures: What Actually Drives Performance
Indexing strategy determines the trade-off between recall, speed, and memory.
HNSW (Hierarchical Navigable Small World Graph)
Used by: Pinecone, Weaviate, Qdrant, Milvus
Characteristics:
- Extremely fast retrieval
- High recall (often >95%)
- Good balance of speed and accuracy
- Memory-heavy due to graph structure
This is the default choice for most production RAG workloads.
IVF (Inverted File Index)
Used by: FAISS, Milvus, some Pinecone configs
Characteristics:
- Clusters vectors into centroids
- Search is restricted to a subset of clusters
- Very effective for large datasets (100M+ vectors)
- Slight recall loss unless combined with re-ranking or PQ
Popular for billion-scale deployments.
Flat Index (Brute Force)
Characteristics:
- Computes distance to every vector
- Perfect recall
- Linear time; impractical beyond small datasets
Good for experimentation and small corpora.
PQ (Product Quantization)
Used by: FAISS, Milvus, Pinecone
Characteristics:
- Compresses vectors into compact codes
- Greatly reduces memory footprint
- Trades some recall for cost and scale
PQ is common where RAM is a serious constraint.
Disk-Based Indexing (DiskANN-style)
Characteristics:
- Optimized for SSD instead of RAM
- Enables cost-efficient billion-scale retrieval
- Slightly higher latency versus RAM indexes
A natural direction for extremely large RAG systems.
The Recall–Latency–Cost Triangle
Every vector retrieval system must balance:
- Recall – how many truly relevant results are found
- Latency – how fast results are returned
- Cost – memory, storage, and compute resources
You can improve any two, but rarely all three at once. Production design always reflects a chosen point in this triangle.
Retrieval Failure Modes
Common failure modes in RAG systems include:
- Missing relevant chunks → hallucinations or incomplete answers
- Redundant chunks → repetitive or low-value context
- Latency spikes → agent workflows time out or degrade
- Embedding drift → mixing incompatible embedding models lowers recall
- Poor chunking → semantically broken segments destroy retrieval quality
These issues are usually architectural, not “model problems”.
Why Vector Databases Matter Even More for Agentic AI
Agentic systems differ from simple RAG chatbots in several ways:
- They perform multi-step reasoning, not one-shot responses.
- They often handle tool calls, planning, and execution.
- They maintain episodic and semantic memory.
- They may coordinate multiple agents working together.
This leads to heavier requirements on the vector store:
- Very low latency across many sequential retrievals
- Real-time inserts and updates as agents learn
- Strong consistency of the memory view between steps
- Safe parallel queries from multiple agents
- Support for multiple memory types (task context, knowledge, episodes)
In practice, a single agentic workflow may trigger dozens or hundreds of vector queries. Any instability in the vector database surfaces immediately as unreliable behavior.
Overview of Leading Vector Databases for RAG and Agentic AI
Pinecone — Managed, Production-Grade Vector Database
Pinecone is a fully managed, cloud-native vector database designed for production AI workloads.
Key characteristics:
- HNSW and IVF-based indexes in RAM
- Serverless or dedicated pod-based scaling
- High recall with low and predictable latency
- Built-in replication and automatic scaling
- Deep integrations with LangChain, LlamaIndex, and other frameworks
Strengths
- Very fast and stable for most RAG workloads
- Minimal DevOps burden
- Strong metadata filtering and namespace support
- Excellent for latency-sensitive agent loops
Weaknesses
- Cloud-only (no self-host)
- Can be expensive at very large scale
- Index warm-up behavior must be managed for dynamic scaling
Best suited for
- Enterprise RAG
- Real-time agent assistants
- Production systems requiring predictable performance
Weaviate — Feature-Rich Open-Source Vector Database
Weaviate is a schemaful, open-source vector database that emphasizes hybrid search and flexible modeling.
Key characteristics:
- HNSW index with live re-indexing
- Hybrid search (BM25 + vector)
- Strong metadata and filtering capabilities
- Class-based schemas and modules for text, images, and more
- Available as open-source or managed cloud
Strengths
- Powerful hybrid search (keyword + vector)
- Strong support for filters and structured metadata
- Flexible schema design for complex applications
- Good ecosystem integrations (Hugging Face, RAG tools)
Weaknesses
- More operational complexity than managed services
- Clustering and scaling need careful planning
- Higher memory requirements in some configurations
Best suited for
- Enterprise search and knowledge portals
- Multi-agent systems with rich filtering
Organizations that prefer self-hosting or hybrid cloud
Qdrant — Cost-Efficient, Rust-Powered Vector Database
Qdrant is an open-source vector database written in Rust, optimized for performance and efficient resource usage.
Key characteristics:
- High-performance HNSW implementation
- Good write performance and real-time updates
- Lightweight resource footprint
- Available as self-hosted and Qdrant Cloud
Strengths
- Very strong cost-performance ratio
- Excellent for dynamic, frequently updated datasets
- Simple API (REST/gRPC) and developer-friendly tooling
- Well-suited as agent memory store
Weaknesses
- Fewer built-in hybrid search capabilities than Weaviate
- Fewer enterprise-oriented features compared to Milvus
Best suited for
- Agentic RAG with constantly evolving memory
- Cost-sensitive RAG systems
Local and on-prem deployments with limited resources
FAISS — The Core ANN Library (Not a Database)
FAISS (Facebook AI Similarity Search) is a highly optimized library for ANN search rather than a database.
Key characteristics:
- Implements a wide range of index types (Flat, IVF, HNSW, PQ, etc.)
- CPU and GPU acceleration
- Often used as the underlying engine inside other vector systems
Strengths
- Extremely fast ANN search, especially on GPU
- Very flexible index configurations
- Ideal for custom retrieval pipelines and research
Weaknesses
- No persistence layer
- No metadata filtering
- No clustering, replication, or DB features
- Requires engineering effort to integrate safely into systems
Best suited for
- Offline or embedded retrieval
- On-device and edge AI
- Research and experimental systems
Milvus — Distributed Vector Database for Massive Scale
Milvus is a distributed, open-source vector database built for very large-scale workloads.
Key characteristics:
- Distributed IVF and HNSW indexes
- Horizontal sharding and replication
- Hybrid search (vector + scalar filters)
- Supports multi-tenancy and RBAC
Strengths
- Very strong for 100M–10B+ vector workloads
- Good fit for search engines and analytics platforms
- On-prem and cloud deployment flexibility
Weaknesses
- Higher operational overhead
- More complex to maintain and tune
- Often overkill for small or medium RAG systems
Best suited for
- Enterprise-level search platforms
- Organizations with stringent control and compliance needs
High-throughput retrieval with large historical corpora
Elasticsearch (with Vector Support) — For Existing ELK Stacks
Elasticsearch is not a pure vector database but increasingly supports vector and hybrid search.
Strengths
- Familiar tooling in organizations already using ELK
- Rich metadata filtering and log search
- Convenient for incremental adoption of semantic search
Weaknesses
- Vector search performance lags specialized vector DBs
- Can be expensive to run at scale
- ANN capabilities are relatively newer and less mature
Best suited for
- Organizations already committed to Elasticsearch
Compliance-heavy environments where tooling and governance are built around ELK
LlamaIndex Storage Layer — Orchestration and Retrieval Logic
LlamaIndex is not a database but provides an abstraction layer over vector stores:
- Manages chunking and document indexing strategies
- Provides advanced retrievers (graph-based, composable, routing)
- Integrates with Pinecone, Weaviate, Qdrant, Milvus, FAISS, and others
Think of it as a retrieval and knowledge orchestration layer that sits above vector databases and agent frameworks.
Comparison Table: Vector Databases for RAG & Agentic AI
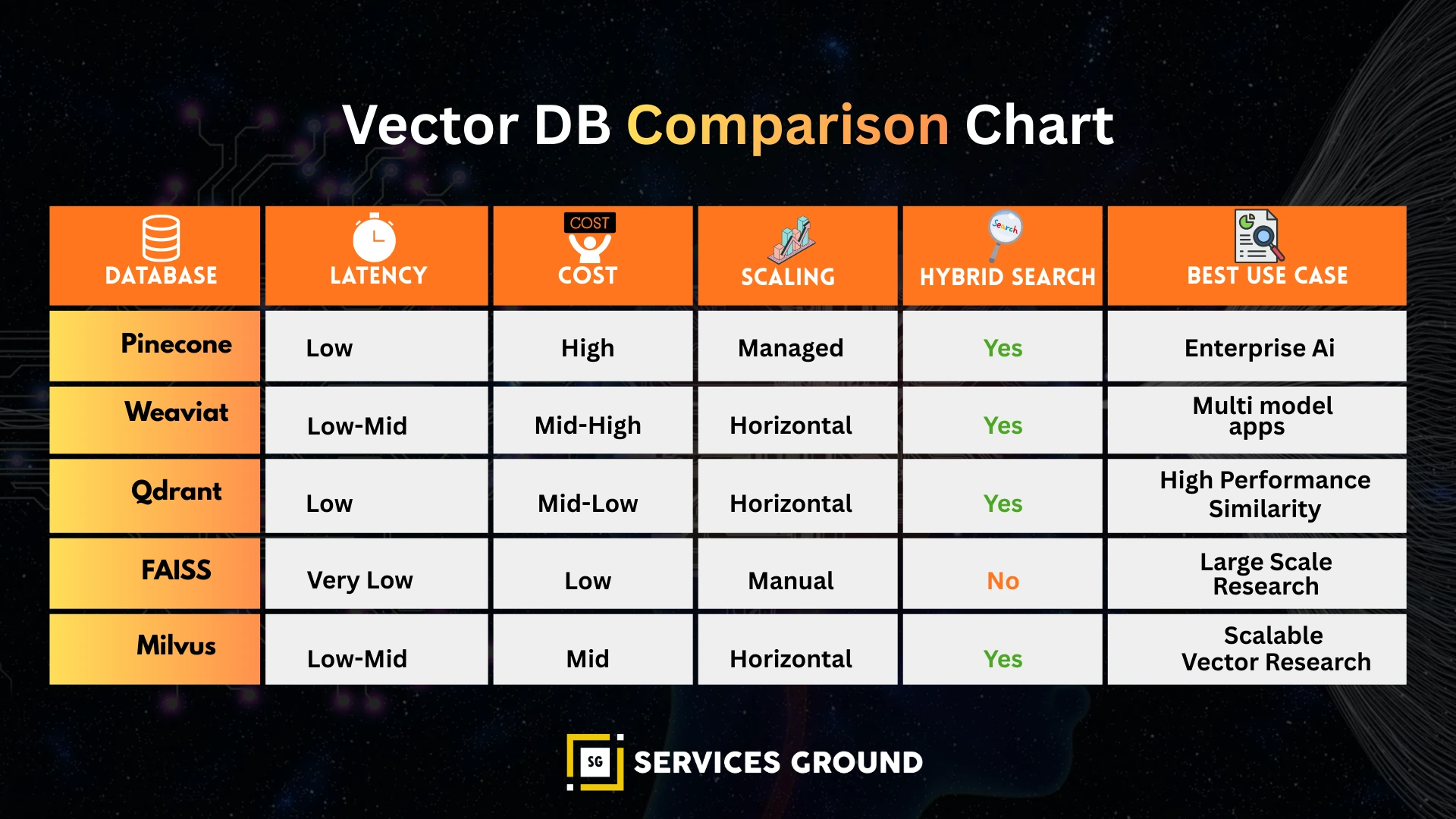
| Vector DB | Best For | Strengths | Weaknesses | Typical Use Case |
|---|---|---|---|---|
| Pinecone | Low-latency RAG at scale | Predictable performance, serverless, high recall | Cloud-only, can be costly at very large scale | Production RAG, enterprise search, agent assistants |
| Weaviate | Hybrid search & rich filtering | Strong hybrid search, schema, metadata filters | More complex to operate | Enterprise knowledge search, multi-agent search systems |
| Qdrant | Dynamic agent memory, cost-efficiency | Fast inserts, Rust performance, efficient resource usage | Fewer hybrid features than Weaviate | Agentic RAG, episodic memory, retrieval-heavy agents |
| FAISS | Local/offline high-speed search | Fastest ANN library, especially on GPU | No DB, no filters, no persistence | Embedded search, research pipelines, on-device retrieval |
| Milvus | Massive-scale deployments | Distributed indexing, sharding, scale to billions | Operational overhead | Search engines, large enterprise vector infrastructure |
| Elasticsearch + Vectors | Existing ELK organizations | Familiar tools, strong filtering | Slower ANN, higher infra cost | Compliance-heavy orgs extending existing ELK deployments |
Operational Considerations for Agentic AI Workloads
Agentic systems place special demands on vector databases.
Latency Budget
Each reasoning loop may include multiple retrieval steps. A typical target:
- <50 ms per vector query for highly interactive agents
- <100–150 ms for standard RAG questions
Anything significantly higher leads to slow and brittle workflows.
Real-Time Upserts
Agent memory must evolve:
- New user interactions
- Agent reflections and lessons learned
- Updated knowledge or logs
The vector database must support low-latency inserts and updates without causing large latency spikes.
Consistency
Two consecutive reasoning steps should not see contradictory memory states. This typically requires:
- Well-defined consistency semantics
- Careful management of eventual consistency in distributed setups
Parallelism
Multi-agent systems and multi-tenant workloads require safe, efficient parallel retrieval:
- No locking bottlenecks
- Predictable performance under concurrency
Hybrid Retrieval
Agents often need to mix:
- Background domain knowledge
- Task-specific context
- Episodic memory of prior decisions
This pushes toward hybrid retrieval setups: vector similarity + keyword + filters + reranking.
Real-World Performance Patterns
While exact numbers depend on hardware and configuration, some stable patterns appear in practice:
- Pinecone tends to lead on managed, RAM-resident HNSW workloads where tail latency consistency matters.
- FAISS (GPU) is often fastest for pure ANN search when you control the full pipeline and run locally.
- Qdrant performs particularly well when balancing reads and writes in dynamic memory scenarios.
- Weaviate tends to outperform others in workloads heavily dependent on hybrid and metadata-rich search.
Milvus scales better than most when vector counts reach hundreds of millions or billions.
Use Cases: Which Vector DB Fits Which Job?
Traditional RAG Pipelines (Q&A, Knowledge Retrieval)
- Good choices: Pinecone, Weaviate.
- Why: Need low latency, high recall, filters, and stable behavior.
- Alternatives: Qdrant for cost-sensitive deployments.
Agentic AI with Dynamic Memory
- Agents constantly write new memories: reflections, logs, outcomes.
- Good choice: Qdrant (cost-efficient, real-time upserts).
- Alternative: Pinecone serverless for managed cloud environments.
Multi-Agent Workflows (CrewAI, LangGraph, etc.)
- Requires rich filtering, hybrid search, and multi-tenant isolation.
- Good choice: Weaviate, due to strong hybrid + schema + filtering support.
Compliance and On-Prem Requirements
- Good choice: Milvus (and/or Weaviate/Qdrant self-hosted).
- Fits environments where data cannot leave controlled infrastructure.
Edge and Offline AI
- Good choice: FAISS
Perfect for embedded/edge inference and offline retrieval.
Architecture Patterns for RAG and Agentic AI
1. Classic RAG Pipeline
User Query ↓ LLM Pre-Processor / Rewriter ↓ Embedding Model ↓ Vector Database (Pinecone / Weaviate / Qdrant) ↓ Top-k Retrieval (+ optional metadata filters) ↓ Re-Ranker (cross-encoder or rerank model) ↓ LLM Answer Generation
Used for:
- Q&A systems
- Documentation search
- Support bots
2. Agentic RAG with Episodic Memory
Agent Step N ↓ LLM Planner ↓ [Branch 1] Knowledge Retrieval → Vector DB (docs) [Branch 2] Episodic Memory Retrieval → Vector DB (memories) ↓ Merge + Rerank Context ↓ LLM Reasoner ↓ Tool Call / Action ↓ Store New Memory (Qdrant / Pinecone / Weaviate) ↓ Agent Step N+1
Used for:
- Long-running workflows
- Assistants that “learn” over time
Research and investigation agents
3. Distributed Enterprise RAG
Client Query ↓ API Gateway / Load Balancer ↓ Multiple Retrieval Nodes ↓ Sharded Vector DB Cluster (Milvus / Weaviate / Elasticsearch+Vectors) ↓ Results Aggregation + Deduplication + Reranking ↓ LLM Response Engine
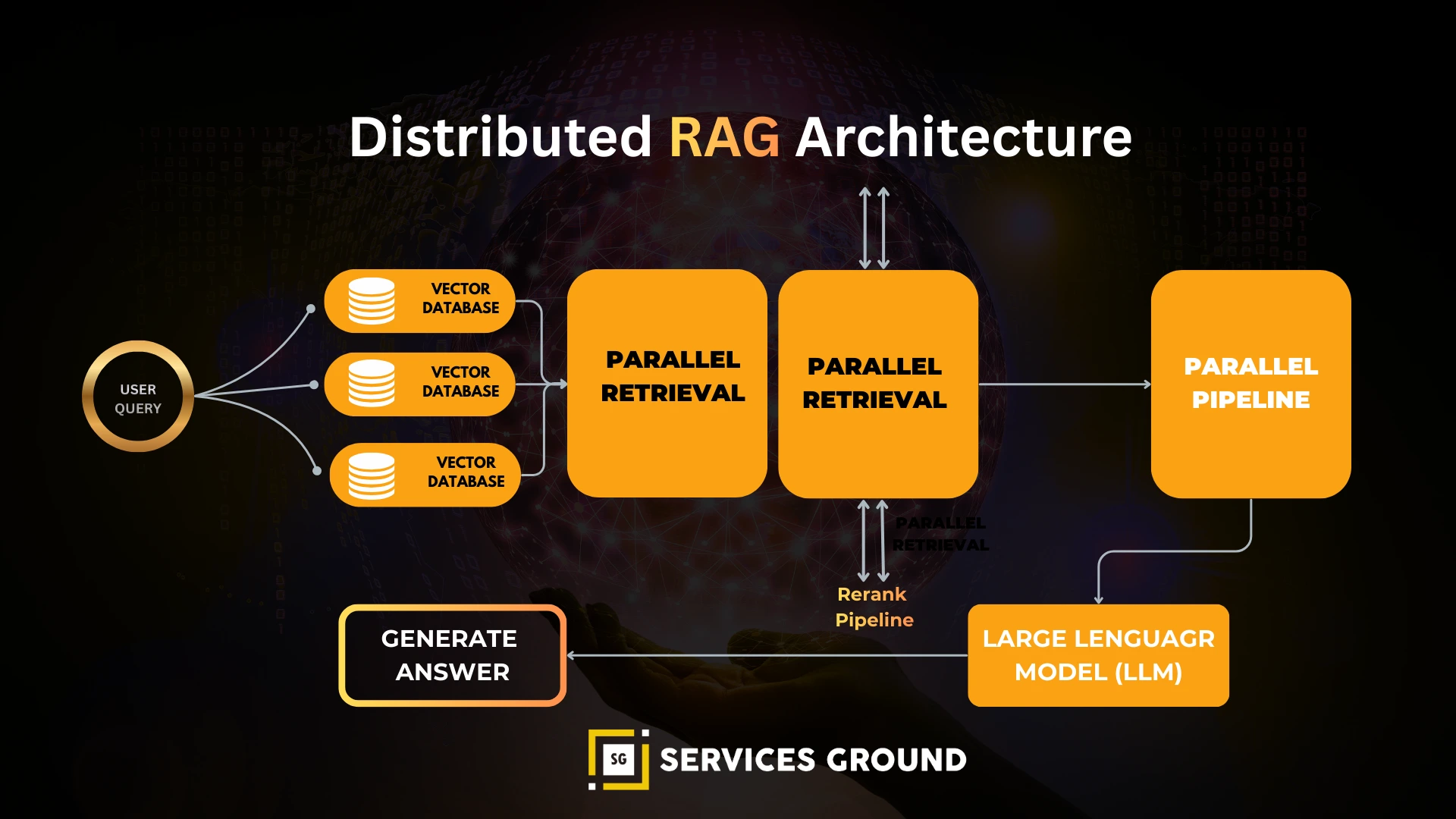
Used for:
- Large search engines
- Enterprise-wide knowledge platforms
- High-throughput analytic retrieval
Common Production Failures and How to Fix Them
Failure 1 — Irrelevant or Weak Results
Causes
- Naive fixed-size chunking
- Poor embedding model choice
- Too aggressive filtering
Fixes
- Use semantic or recursive chunking (200–500 tokens)
- Upgrade embeddings
- Add reranking on top of vector retrieval
Failure 2 — Low Recall
Causes
- Under-tuned index parameters (e.g., low ef_search or nprobe)
- Incorrect similarity metric
- Very small top-k
Fixes
- Increase search parameters and top-k
- Verify metric compatibility with embedding model
- Add a reranker with richer context window
Failure 3 — Latency Too High for Agents
Causes
- Remote vector DB in a different region
- Heavy filters or complex queries
- Very high dimensional embeddings
Fixes
- Co-locate vector DB near the model/agents
- Reduce embedding dimensionality when possible
- Tune index type and query parameters for speed
Failure 4 — Memory Gets Stale
Causes
- No strategy for updating or pruning memory
- Agents not writing back new knowledge
- Embeddings not refreshed after schema/content changes
Fixes
- Implement real-time upserts for new knowledge
- Use time-weighted or recency-aware retrievers
- Periodically re-embed critical slices of the corpus
Failure 5 — Hallucinations Despite RAG
Causes
- The right documents exist but are never retrieved
- Overly narrow retrieval (too few diverse chunks)
- No guardrails on answer generation
Fixes
- Increase context diversity (wider retrieval across sources)
- Use hybrid search (keyword + vector) where appropriate
Add answer validation or post-hoc checking for critical tasks
Example: Agentic RAG for API Troubleshooting
Consider an AI support agent helping developers debug API issues.
- User query
“My API returns 403 when calling /auth/verify.”
- Planner step
The agent decides it needs:
- API documentation
- Authentication error FAQs
- Similar past tickets or incidents
- API documentation
- Retrieval
- Queries Pinecone or Qdrant with the error description
- Retrieves top relevant documents (docs, logs, previous incidents)
- Queries Pinecone or Qdrant with the error description
- Reranking & reasoning
- Reranks snippets with a cross-encoder
- The LLM reasons over the top context and identifies likely root causes
- Reranks snippets with a cross-encoder
- Action
- Suggests concrete fix (e.g., missing header, invalid token scope)
- Writes a brief explanation
- Stores this interaction as a new episodic memory for future retrieval
- Suggests concrete fix (e.g., missing header, invalid token scope)
- Continuous improvement
Over time the agent builds a library of high-value cases, which improves future retrieval and accelerates troubleshooting.
In this pattern, the vector database is central: it serves as both knowledge base and memory, supporting both RAG and long-term agent learning.
Conclusion
Vector databases are not a peripheral detail in modern AI systems; they are the infrastructure layer that determines whether RAG and agentic AI work reliably in production.
- They store and retrieve semantic context at scale.
- They underpin long-term memory for agents.
- They shape latency, recall, and reliability.
- They must be chosen and tuned with workload realities in mind.
Pinecone, Weaviate, Qdrant, FAISS, and Milvus each excel in different scenarios. There is no single “best” vector database, only the best fit for a given architecture, scale, and set of constraints.
If you design retrieval, memory, and vector infrastructure as a first-class part of your agentic stack, not an after thought you get systems that reason better, respond faster, and improve over time.
You can also follow us on Facebook, Instagram, Twitter, Linkedin, or YouTube.
Frequently Asked Questions
A vector database stores high-dimensional embeddings and retrieves semantically similar items using approximate nearest neighbor (ANN) search.
In RAG (Retrieval-Augmented Generation), LLMs rely on these retrieved embeddings as grounding context.
Without a vector database, RAG systems cannot consistently surface relevant information, which leads to hallucinations and incomplete answers.
There is no universal “best,” but consistent patterns emerge:
- Pinecone → best managed, lowest latency, production-ready
- Weaviate → best hybrid (keyword + vector) search
- Qdrant → best cost-performance and dynamic agent memory
- Milvus → best for massive (100M–10B+) scale
- FAISS → best for local/offline or experimental retrieval
Your ideal choice depends on latency requirements, dataset size, update frequency, and whether you need cloud or self-hosting.
RAG output is only as good as the documents retrieved.
Common failure scenarios include:
- Missing relevant context (low recall)
- Returning redundant or irrelevant chunks
- Embedding drift leading to mismatched similarity
- Chunking errors causing semantic gaps
When retrieval fails, the LLM hallucinates—even if the right answer exists in your knowledge base.
No. They complement, not replace.
Vector search excels at semantic meaning, but keyword search excels at:
- Exact filtering
- Compliance queries
- High-precision lookups
- Boolean operations
Modern RAG architectures combine both using hybrid search—a domain where Weaviate and Milvus particularly shine.
Agentic systems repeatedly retrieve context throughout reasoning loops:
- Planning
- Tool execution
- Multi-step workflows
- Episodic memory recall
- Learning from past actions
Because agents retrieve dozens or hundreds of times per task, the vector DB becomes the long-term memory substrate that allows agents to learn, recall, and adapt.
- HNSW → high recall + low latency (best general-purpose choice)
- IVF → excellent for extremely large datasets (100M–1B vectors)
- PQ → compresses vectors for cost-efficient storage
- Flat index → perfect recall but too slow for large systems
Production RAG typically uses HNSW, while billion-scale deployments often combine IVF + PQ.
FAISS is not a vector database—it's an ANN library.
You must build your own:
- index management
- persistence
- metadata filtering
- replication
- API layer
Use FAISS for local offline pipelines, not production-grade retrieval.
Optimal chunk sizes for RAG typically fall between:
- 200–500 tokens for general-purpose retrieval
- 800–1200 tokens for technical documentation
- 150–250 tokens for conversational agents with high context switching
Better chunking improves recall more than changing database engines.
Hybrid search combines:
- keyword/BM25 search
- vector semantic search
- metadata filtering
It helps prevent:
- semantic drift
- missed exact matches
- poor performance on rare or domain-specific terms
Weaviate and Milvus lead in hybrid search capability.