



AI Agent Benchmarks: How Autonomous Agents Are Evaluated in Real Systems
Modern AI systems are no longer evaluated solely on language quality or model accuracy. As systems evolve into autonomous agents that reason, plan, use tools, browse the web, and execute multi-step workflows, evaluation becomes fundamentally more complex.
This is where AI agent benchmarks come in.
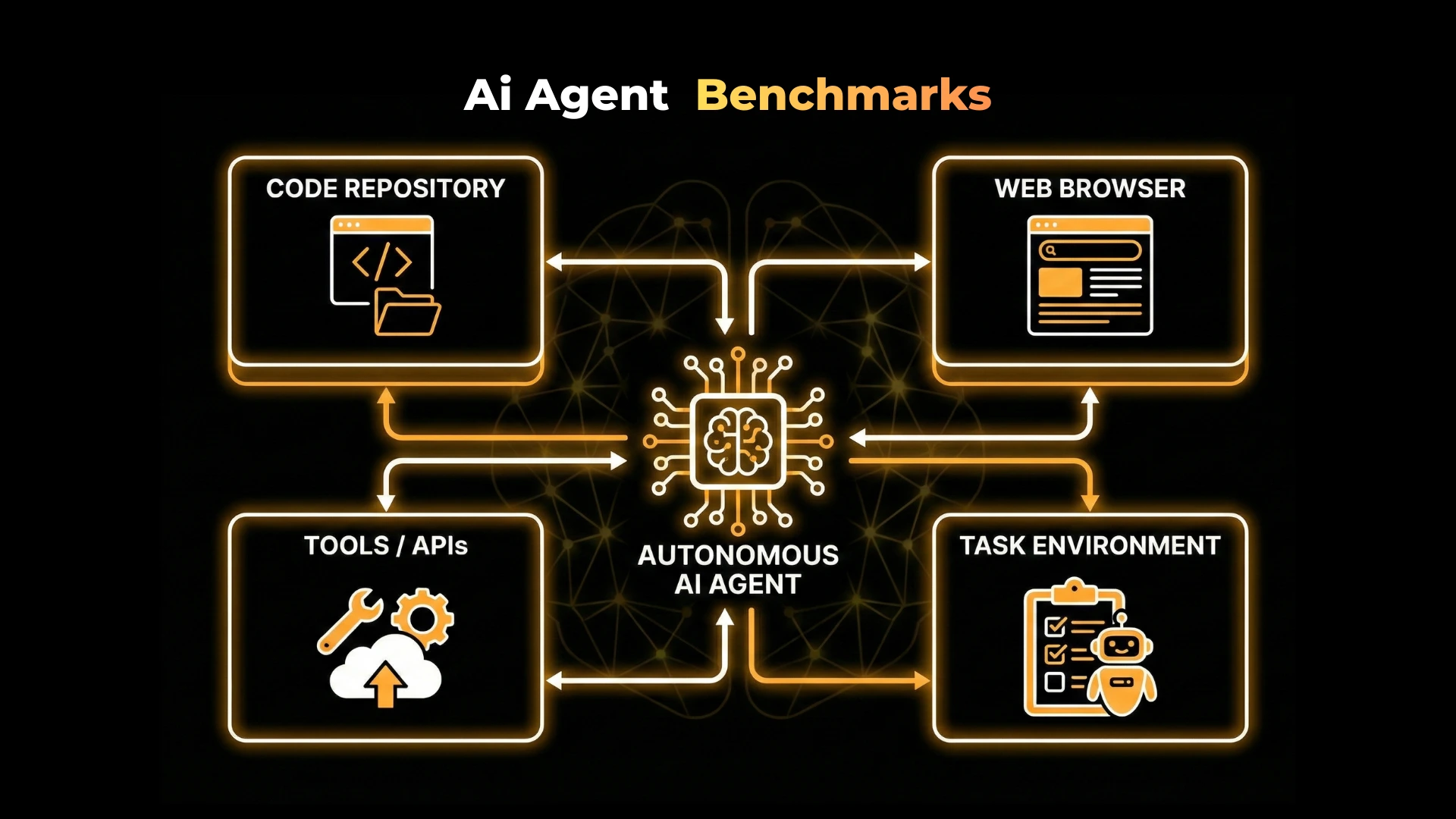
Unlike traditional LLM benchmarks, agent benchmarks attempt to measure whether an agent can successfully complete tasks in dynamic environments, using tools, maintaining state, recovering from errors, and making decisions across multiple steps. These benchmarks are not just academic artifacts; they shape how agentic systems are designed, compared, and deployed in production.
Why Evaluating AI Agents Is Harder Than Evaluating Models
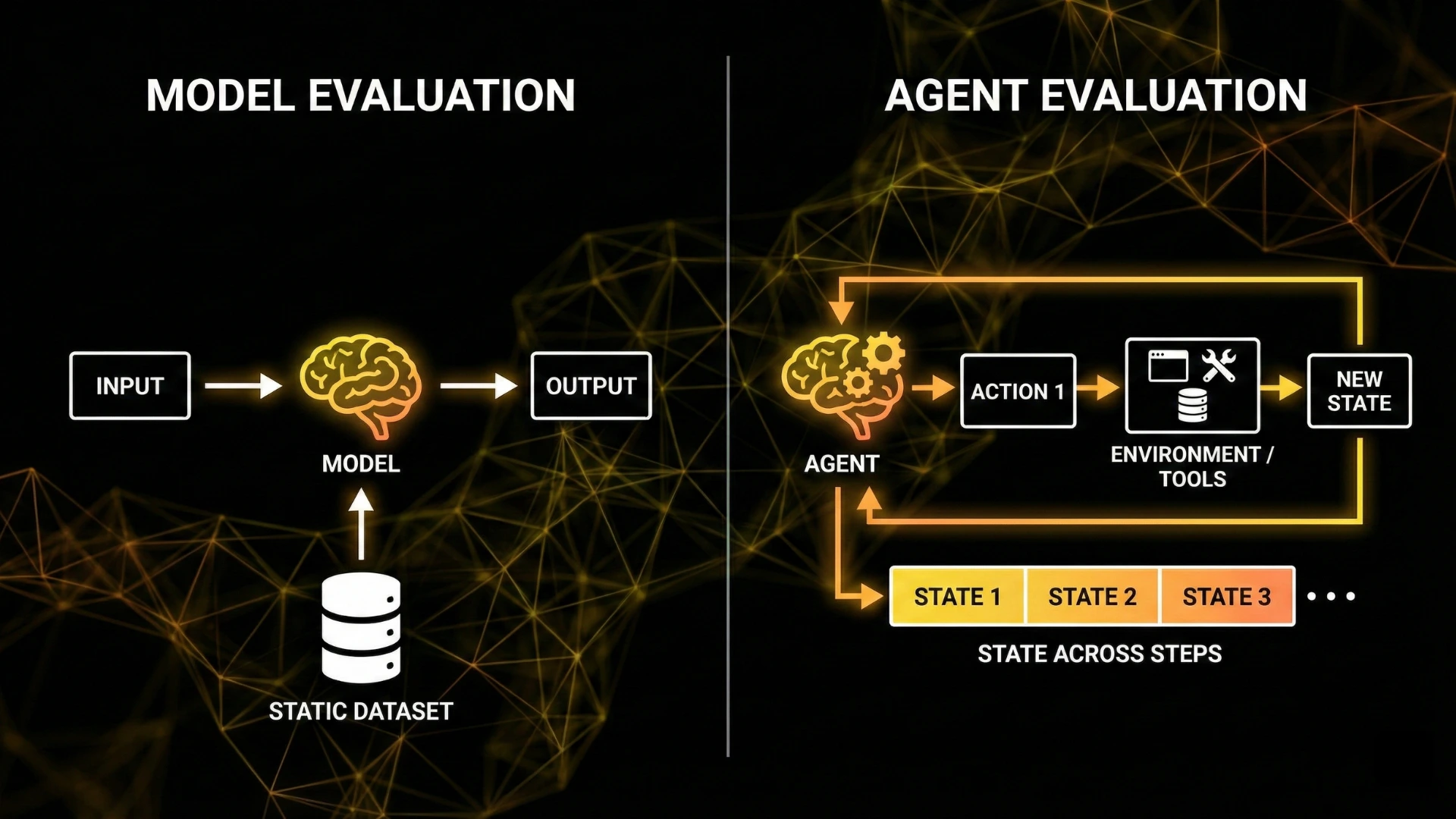
Traditional model evaluation focuses on static outputs:
- Accuracy on labeled datasets
- BLEU, ROUGE, or exact match
- Preference rankings or human judgment
Agents break this paradigm.
- Performs multiple actions
- Interacts with external environments
- Uses tools and APIs
- Maintains state across steps
- Adapts its plan based on intermediate results
Evaluation must therefore account for process, not just output.
Key differences between model evaluation and agent evaluation:
- Success is often binary or conditional (task completed or not)
- There may be multiple valid solution paths
- Intermediate steps matter as much as final answers
- Failures are often systemic (planning, memory, tool use), not linguistic
This is why AI agent benchmarks focus on tasks, environments, and trajectories, rather than static prompts.
What Makes a Good AI Agent Benchmark
A useful AI agent benchmark must satisfy several criteria:
1. Environment Realism
The benchmark should simulate real-world constraints:
- Incomplete information
- Delayed feedback
- Brittle interfaces
- noisy environments
2. Multi-Step Task Structure
Single-step benchmarks fail to capture planning and recovery. Good benchmarks require:
- Sequencing
- Decision points
- Conditional branching
3. Action Grounding
Agents must interact with:
- Tools
- Files
- Browsers
- Codebases
- APIs
Pure text-only tasks do not reflect agent behavior.
4. Clear Success Criteria
Success must be objectively verifiable:
- Tests pass
- State matches expected outcome
- Environment goals are satisfied
5. Diagnostic Power
A good benchmark reveals why an agent fails:
- Planning error
- Tool misuse
- Hallucinated assumptions
- State inconsistency
Benchmarks that only output a score but offer no insight are limited in engineering value.
Core Metrics Used in AI Agent Benchmarks
Across modern AI agent benchmarks, several metrics appear consistently:

Task Success Rate
The percentage of tasks completed correctly. This is the most visible metric but often the least informative alone.
Step Efficiency
How many actions or steps the agent takes relative to an optimal solution. Inefficient agents may succeed but be impractical.
Tool-Use Accuracy
Whether the agent calls the correct tool, with correct parameters, at the right time.
Groundedness
The degree to which agent actions and outputs are supported by retrieved or observed information rather than hallucination.
Latency
Time to completion, often reported as:
- Mean latency
- p95 / p99 latency for long workflows
Error Recovery Rate
How often an agent can recover from partial failure instead of collapsing the task.
No single metric is sufficient. Real evaluation requires multi-metric interpretation.
SWE-bench: Evaluating Software Engineering Agents
SWE-bench is one of the most influential AI agent benchmarks today.
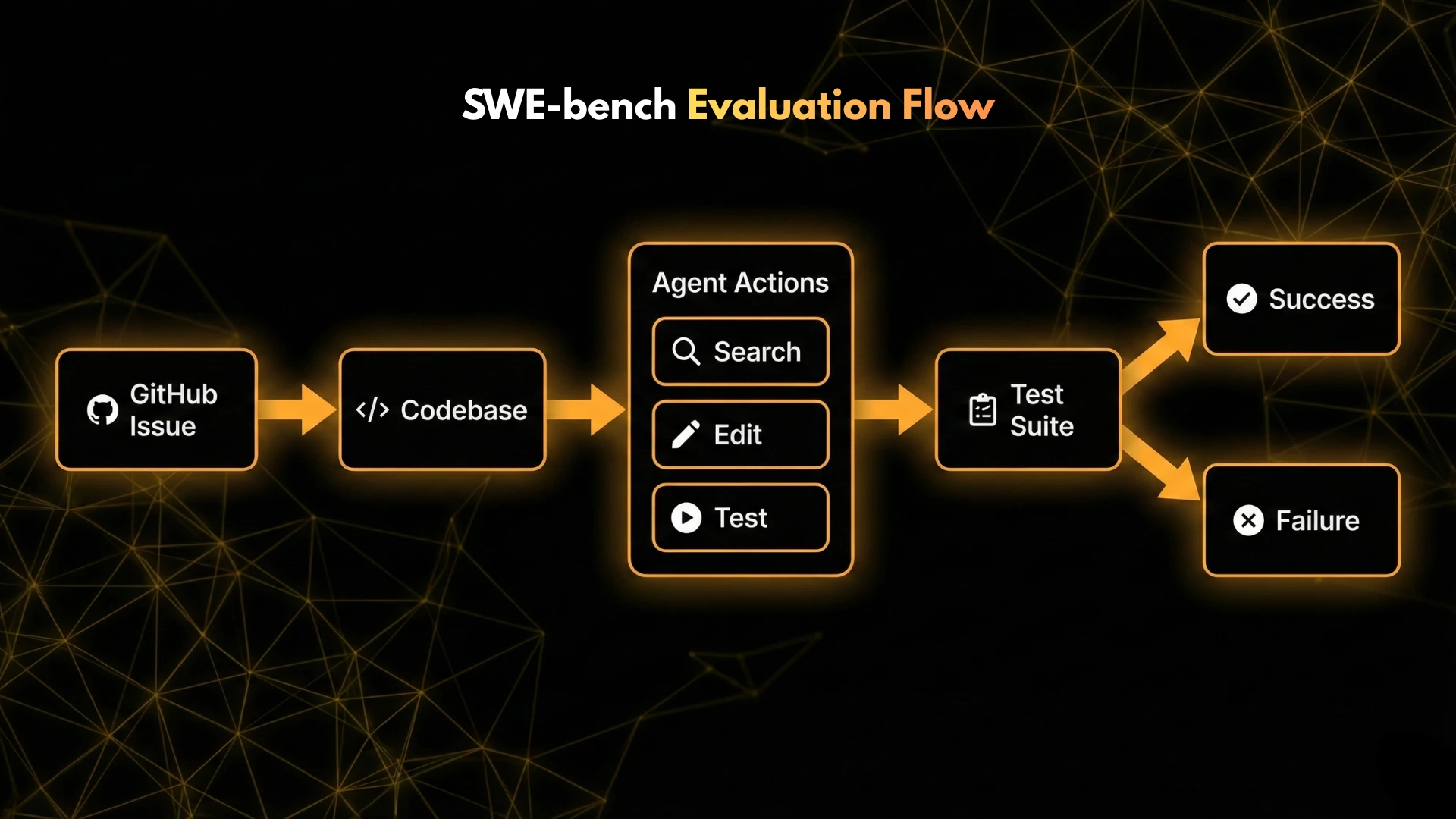
What SWE-bench Measures
SWE-bench evaluates agents on real GitHub issues. The agent is given:
- A repository
- A failing test or bug description
- Access to code and tools
Success is defined as:
- Producing a patch that passes all tests
What It Tests Well
- Long-horizon reasoning
- Code navigation
- Tool usage (edit, search, test)
- Debugging and repair
What It Does Not Measure
- Human-readable explanations
- Efficiency of solution
- Robustness across environments
- Collaborative or multi-agent behavior
Why SWE-bench Matters
SWE-bench is one of the few benchmarks that directly reflects real developer workflows. It exposes failures in:
- Planning
- Context management
- Incorrect assumptions about code behavior
Common Misinterpretation
High SWE-bench scores do not guarantee a general-purpose agent. They indicate strength in software repair tasks, not universal autonomy.
AgentBench: General-Purpose Agent Evaluation
AgentBench aims to evaluate agents across diverse domains rather than a single task type.
Domains Covered
- Reasoning tasks
- Tool usage
- Web interaction
- Data analysis
- Simulated environments
Strengths
- Broad coverage
- Standardized evaluation
- Comparable across models and agents
Limitations
- Environments are often simplified
- Tasks may not reflect production constraints
- Success metrics can hide partial failures
AgentBench is best used to compare agent architectures, not to predict real-world performance directly.
BrowserGym: Evaluating Computer-Using Agents
BrowserGym focuses on browser-based agents that interact with web interfaces.
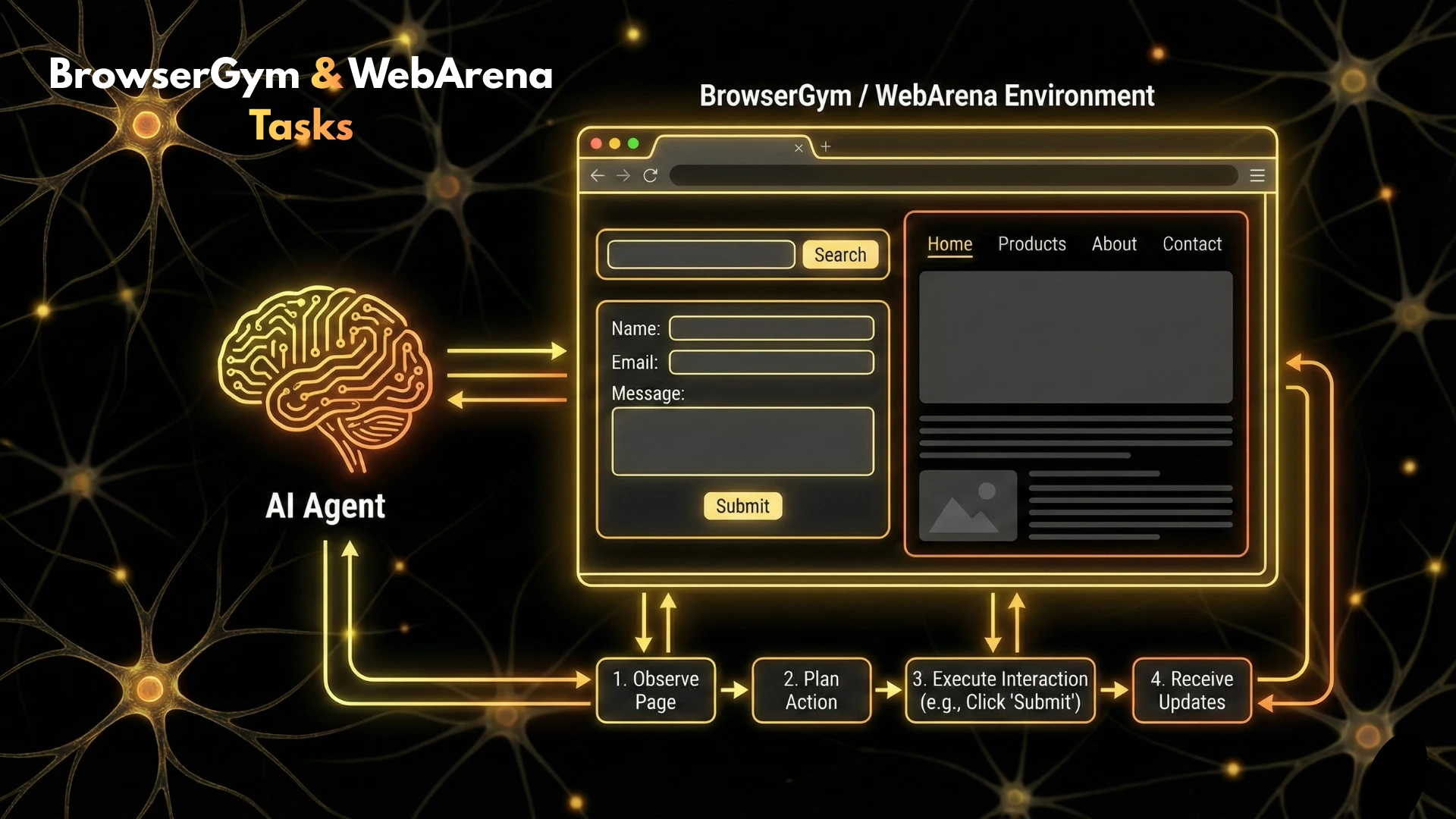
What It Evaluates
- Form filling
- Navigation
- Clicking, scrolling
- Handling UI changes
Why BrowserGym Exists
Browser automation is deceptively difficult:
- DOM structures change
- Instructions are ambiguous
- Errors propagate quickly
BrowserGym reveals failures in:
- Perception
- Action grounding
- Recovery from UI drift
Limitations
BrowserGym environments are controlled. Real websites often introduce:
- Authentication
- Rate limiting
- Dynamic scripts
Despite this, BrowserGym is a critical benchmark for computer-using agents.
WebArena: Realistic Web Task Evaluation
WebArena pushes browser-based evaluation closer to reality.
Key Characteristics
- Realistic websites
- Multi-step objectives
- Long task horizons
- Sparse rewards
What WebArena Tests
- Planning under uncertainty
- Persistence across failures
- Tool sequencing
- Real-world navigation complexity
Why WebArena Is Hard
Many agents fail not because of reasoning errors, but because:
- They lose state
- They misinterpret page context
- They cannot recover from small mistakes
WebArena is one of the strongest benchmarks for testing true autonomy, not scripted automation.
How These Benchmarks Complement Each Other
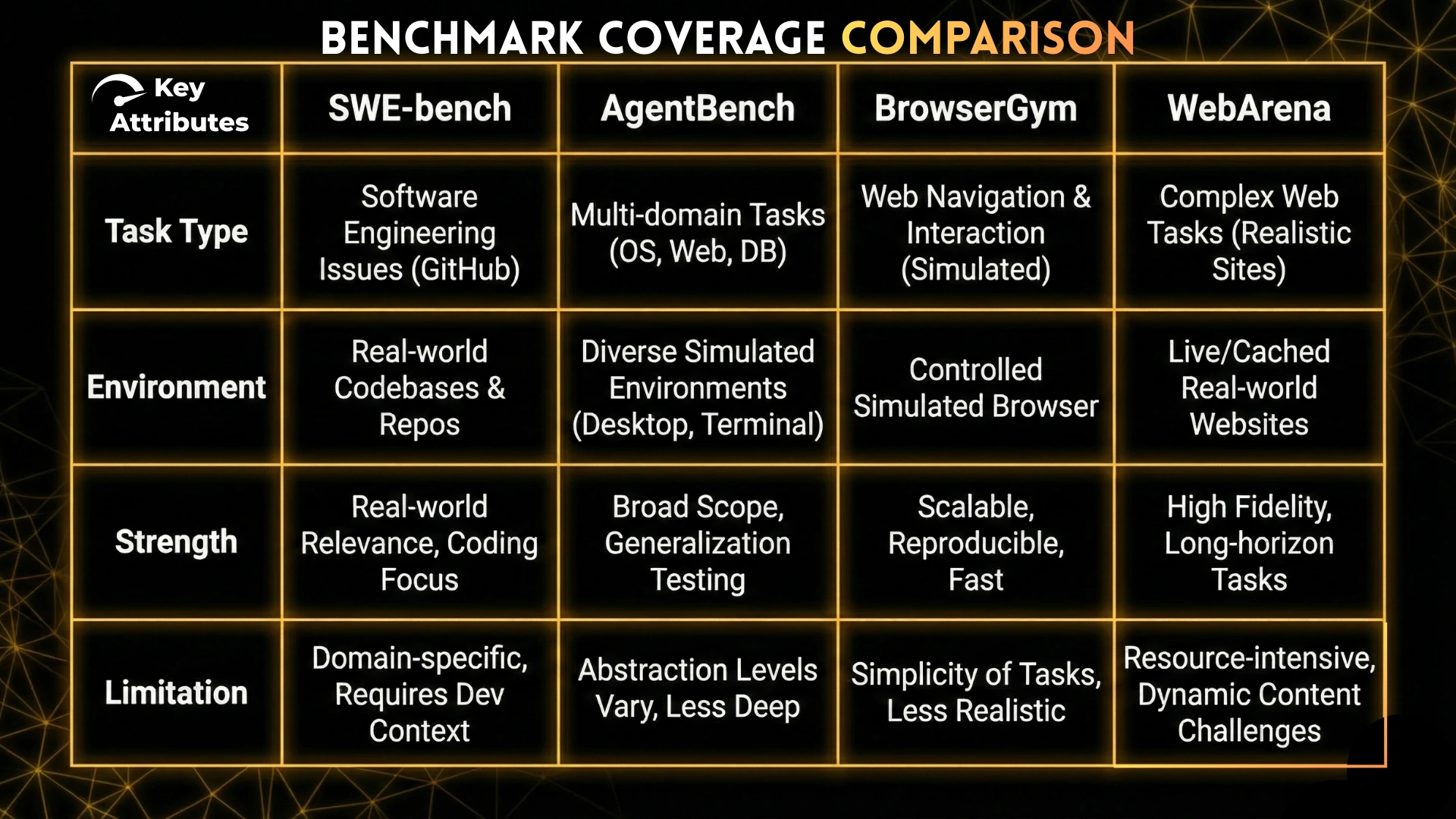
Each benchmark tests a different failure surface:
- SWE-bench → code reasoning and tool grounding
- AgentBench → general decision-making breadth
- BrowserGym → UI interaction reliability
- WebArena → long-horizon real-world behavior
No single benchmark is sufficient. Mature evaluation strategies combine multiple benchmarks to understand where an agent breaks.
What AI Agent Benchmarks Miss
Even the best benchmarks have blind spots.
Benchmarks Do Not Measure Trust
An agent that succeeds 60% of the time may still be unacceptable in regulated or safety-critical domains.
Benchmarks Rarely Measure Cost
Latency, API usage, and compute cost are rarely included but matter in production.
Benchmarks Ignore Organizational Context
Agents deployed in teams must integrate with human workflows, not just complete isolated tasks.
Benchmarks Overfit to Known Tasks
Agents can learn benchmark-specific heuristics without becoming truly robust.
This is why benchmarks should inform design decisions, not replace system-level testing.
How Teams Actually Evaluate Agents in Practice
Production teams rarely rely on a single benchmark.
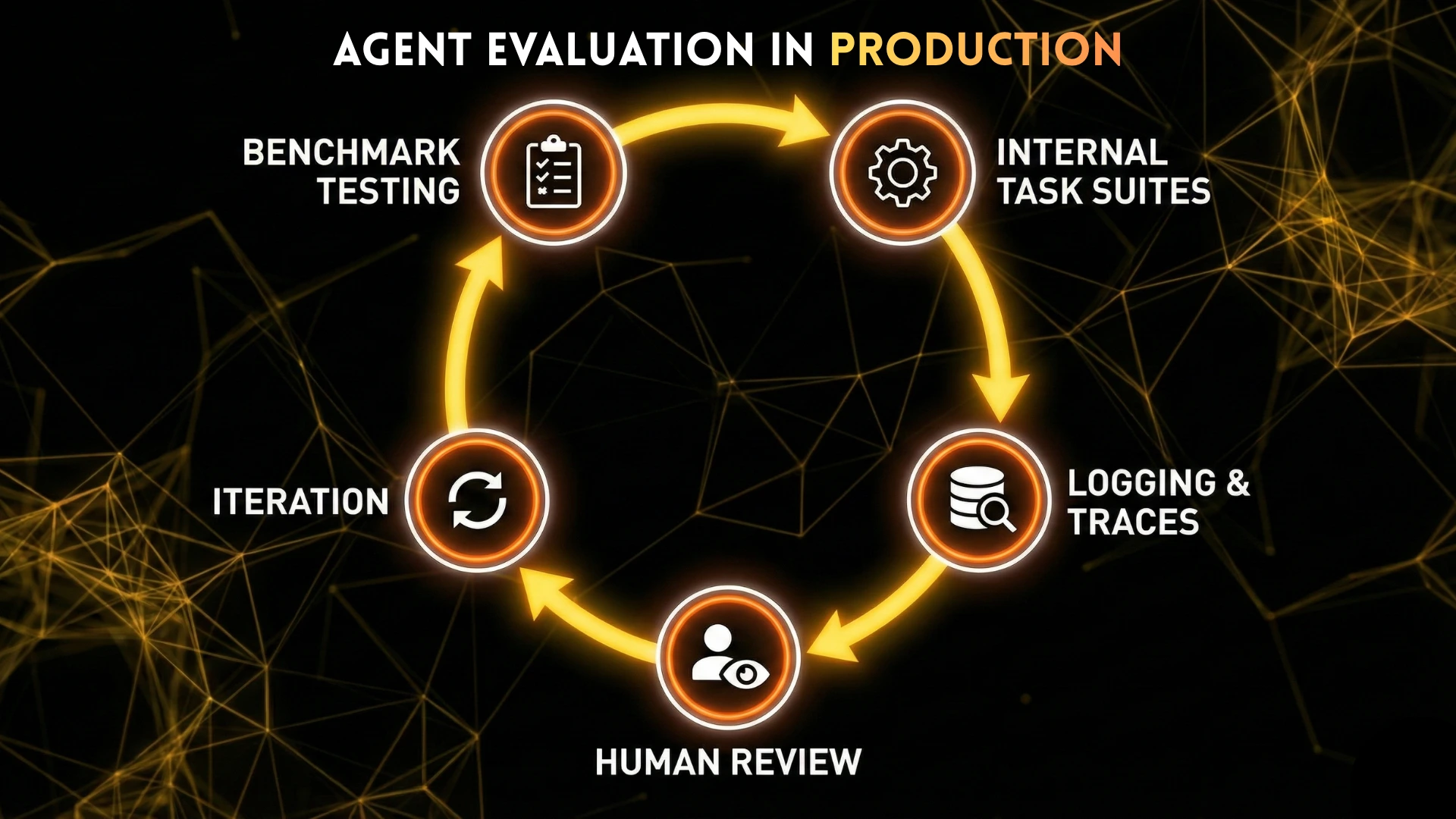
Common evaluation stacks include:
- One or two public benchmarks (e.g., SWE-bench)
- Internal task suites
- Failure case analysis
- Shadow deployment with logging
- Manual review of agent trajectories
Benchmarks answer:
“Can this agent do something?”
Production evaluation answers:
“Can this agent do our work, reliably, safely, and repeatedly?”
Choosing the Right AI Agent Benchmark
Choose based on agent type:
- Software engineering agent → SWE-bench
- General research or reasoning agent → AgentBench
- Browser or computer agent → BrowserGym + WebArena
- Tool-heavy agents → combine benchmarks with tool-specific tests
The best evaluation strategy is layered, not singular.
Conclusion
AI agent benchmarks are essential tools for understanding how autonomous systems behave, but they are not absolute measures of intelligence or reliability.
SWE-bench, AgentBench, BrowserGym, and WebArena each illuminate different aspects of agent behavior. Used together and interpreted carefully, they provide valuable signals for agent design and iteration.
The future of agent evaluation lies not in higher benchmark scores alone, but in diagnostic evaluation, failure analysis, and alignment with real-world constraints. Benchmarks are a starting point — engineering judgment remains indispensable.
Frequently Asked Questions
AI agent benchmarks are standardized task environments used to evaluate how autonomous agents plan, act, and complete multi-step objectives.
Agents are evaluated on task success, tool use, and behavior across time, not just text quality.
No. SWE-bench measures software engineering capability, not general autonomy.
BrowserGym and WebArena are the most relevant benchmarks for browser-based agents.
Benchmarks are indicative, not definitive. Production behavior depends on system design, monitoring, and constraints beyond benchmark scope.