



In the quest for truly intelligent coding assistants, one of the most powerful yet often overlooked resources is documentation. Libraries, frameworks, internal APIs, and coding standards all come with extensive documentation that holds the key to correct usage, best practices, and efficient implementation. But how can we unlock this vast repository of knowledge and make it readily available to AI assistants right within the IDE?
The answer lies in transforming static documentation into dynamic, searchable vector knowledge. By converting documentation into numerical representations (vectors) that capture semantic meaning, we can build AI systems that understand and leverage this knowledge to provide highly accurate, context-aware coding assistance. This process involves sophisticated documentation scraping techniques and efficient storage in vector databases like Chroma DB.
The Challenge: Bridging Documentation and Development
Traditionally, developers face a significant disconnect between their code editor and the documentation they need:
- Context Switching: Developers constantly switch between their IDE and browser tabs to look up documentation.
- Information Overload: Finding the right piece of information in extensive documentation can be time-consuming.
- Outdated Knowledge: Developers might rely on outdated mental models or cached information.
- Inconsistent Application: Ensuring consistent application of best practices across a team is challenging.
AI coding assistants promise to solve these issues, but their effectiveness is limited if they don’t have access to the specific documentation relevant to the project at hand.
The Solution: Documentation as Vector Knowledge
Vector databases and Retrieval-Augmented Generation (RAG) provide a powerful solution by allowing us to:
- Scrape and Process Documentation: Automatically extract content from various documentation sources.
- Convert to Vectors: Use embedding models to transform text into meaningful vector representations.
- Store Efficiently: Store these vectors in a specialized database like Chroma DB for fast retrieval.
- Retrieve Contextually: Find the most relevant documentation based on the developer’s current code context.
- Enhance AI Generation: Use retrieved documentation to inform and improve AI code suggestions.
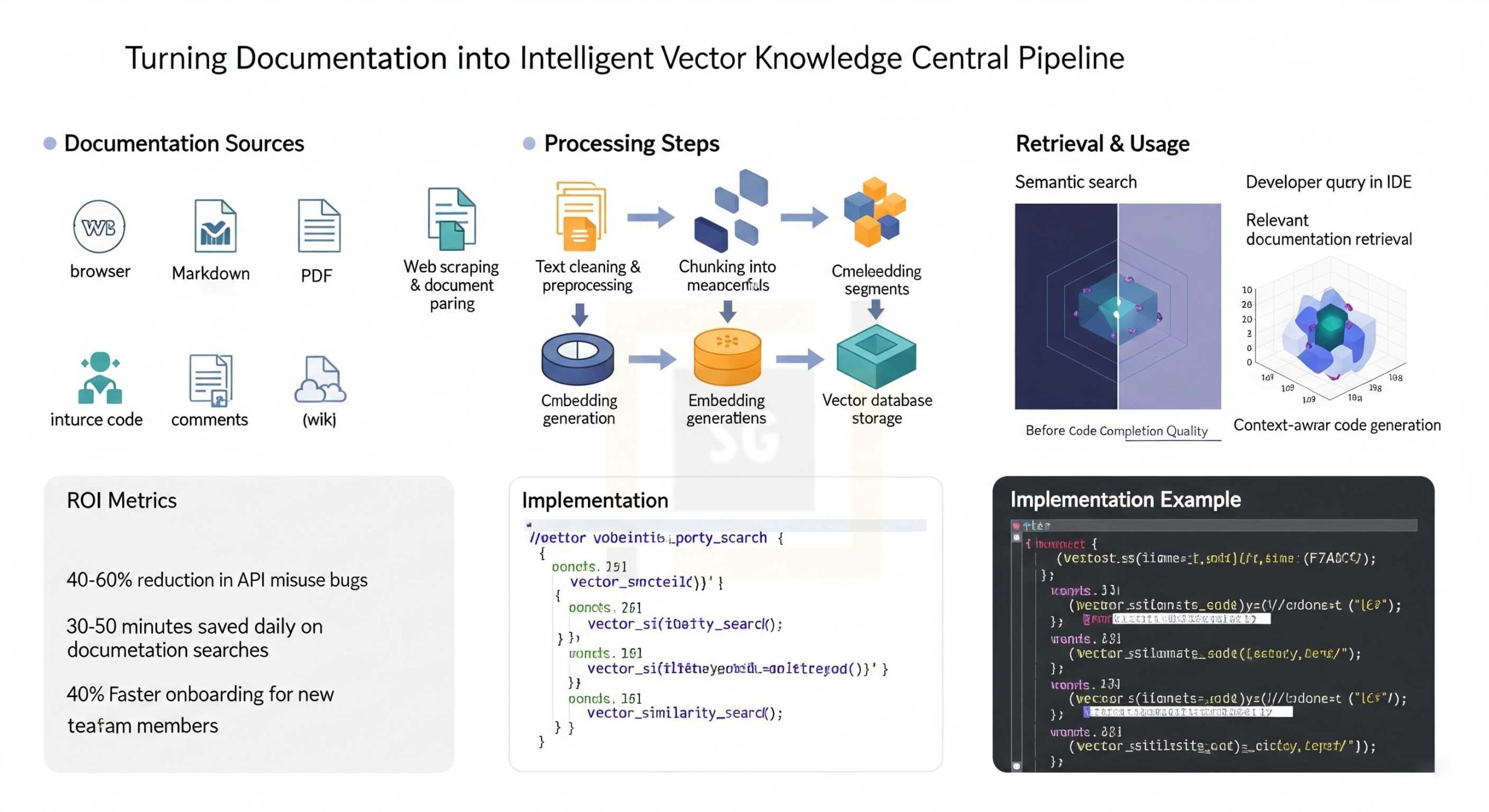
Step 1: Documentation Scraping Techniques
Gathering documentation requires robust scraping techniques tailored to different sources:
Web Scraping for Online Documentation
# Example: Using BeautifulSoup for web scraping
import requests
from bs4 import BeautifulSoup
def scrape_web_documentation(url):
try:
response = requests.get(url)
response.raise_for_status() # Raise HTTPError for bad responses (4xx or 5xx)
soup = BeautifulSoup(response.text, 'html.parser')
# Extract relevant content (adjust selectors based on site structure)
main_content = soup.find('main') or soup.find('article') or soup.find('div', class_='content')
if not main_content:
# Fallback: try to get the body content
main_content = soup.body
if not main_content:
return "Could not find main content area."
# Remove irrelevant elements like navigation, footers, ads
for element in main_content.find_all(['nav', 'footer', 'aside', 'script', 'style']):
element.decompose()
# Extract text, preserving some structure
text_content = main_content.get_text(separator='\n', strip=True)
return text_content
except requests.exceptions.RequestException as e:
print(f"Error fetching URL {url}: {e}")
return None
except Exception as e:
print(f"Error parsing URL {url}: {e}")
return None
# Example usage
react_docs_url = "https://react.dev/reference/react/useState"
scraped_content = scrape_web_documentation(react_docs_url)
if scraped_content:
print(f"Scraped {len(scraped_content)} characters from {react_docs_url}")
Processing Markdown and Source Code Comments
# Example: Processing Markdown documentation
import markdown
from bs4 import BeautifulSoup
def process_markdown_file(filepath):
try:
with open(filepath, 'r', encoding='utf-8') as f:
md_content = f.read()
# Convert Markdown to HTML
html_content = markdown.markdown(md_content)
# Extract text from HTML
soup = BeautifulSoup(html_content, 'html.parser')
text_content = soup.get_text(separator='\n', strip=True)
return text_content
except FileNotFoundError:
print(f"Error: File not found at {filepath}")
return None
except Exception as e:
print(f"Error processing Markdown file {filepath}: {e}")
return None
# Example usage
internal_api_docs_path = "docs/internal_api.md"
processed_content = process_markdown_file(internal_api_docs_path)
if processed_content:
print(f"Processed {len(processed_content)} characters from {internal_api_docs_path}")
Handling PDFs and Other Formats
Specialized libraries are needed for formats like PDF:
# Example: Using PyPDF2 for PDF extraction (requires installation)
# Note: PDF text extraction can be complex and may require OCR for images
# Consider libraries like pdfminer.six or PyMuPDF for more robust extraction
# Placeholder for PDF processing logic
def process_pdf_documentation(filepath):
# Implementation using a PDF library would go here
print(f"Placeholder: Processing PDF documentation from {filepath}")
# Example using a hypothetical library:
# pdf_reader = PDFLibrary(filepath)
# text_content = pdf_reader.extract_text()
# return text_content
return "Sample text extracted from PDF."
# Example usage
style_guide_path = "docs/coding_style_guide.pdf"
pdf_content = process_pdf_documentation(style_guide_path)
if pdf_content:
print(f"Processed content from {style_guide_path}")
Step 2: Vector Representation of Code Knowledge
Once documentation is extracted, it needs to be converted into vectors:
Text Chunking
Large documents are split into smaller, meaningful chunks:
# Example: Using LangChain for text splitting
from langchain.text_splitter import RecursiveCharacterTextSplitter
def chunk_text(text, chunk_size=1000, chunk_overlap=200):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len
)
chunks = text_splitter.split_text(text)
return chunks
# Example usage
long_documentation = "..." # Assume this holds a large scraped document
text_chunks = chunk_text(long_documentation)
print(f"Split document into {len(text_chunks)} chunks.")
Embedding Generation
Each chunk is converted into a vector using an embedding model:
# Example: Using Sentence Transformers for embeddings
from sentence_transformers import SentenceTransformer
# Load model (ideally once at startup)
embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
def generate_embeddings(text_chunks):
embeddings = embedding_model.encode(text_chunks, show_progress_bar=True)
return embeddings
# Example usage
chunk_embeddings = generate_embeddings(text_chunks)
print(f"Generated {len(chunk_embeddings)} embeddings of dimension {chunk_embeddings.shape[1]}")
Step 3: Storing Vectors in Chroma DB
Chroma DB is a popular choice for storing and querying these vectors:
# Example: Storing vectors in Chroma DB
import chromadb
def store_in_chromadb(chunks, embeddings, collection_name="documentation"):
# Initialize Chroma client (persistent storage)
client = chromadb.PersistentClient(path="./chroma_db")
# Get or create collection
collection = client.get_or_create_collection(name=collection_name)
# Prepare data for Chroma
ids = [f"doc_chunk_{i}" for i in range(len(chunks))]
# Assuming metadata like source URL is available
metadatas = [{'source': 'example.com/docs', 'chunk_index': i} for i in range(len(chunks))]
# Add data to collection
collection.add(
embeddings=embeddings.tolist(), # Chroma expects lists
documents=chunks,
metadatas=metadatas,
ids=ids
)
print(f"Stored {len(chunks)} chunks in Chroma collection '{collection_name}'")
# Example usage
store_in_chromadb(text_chunks, chunk_embeddings)
Step 4: Retrieval Strategies for Relevant Context
When a developer needs assistance, the system retrieves relevant documentation:
# Example: Querying Chroma DB for relevant context
import chromadb
def retrieve_from_chromadb(query_text, collection_name="documentation", top_k=5):
# Initialize Chroma client
client = chromadb.PersistentClient(path="./chroma_db")
collection = client.get_collection(name=collection_name)
# Generate embedding for the query
# Assuming embedding_model is loaded globally or passed
query_embedding = embedding_model.encode([query_text])[0]
# Query the collection
results = collection.query(
query_embeddings=[query_embedding.tolist()],
n_results=top_k,
include=['documents', 'metadatas', 'distances']
)
return results
# Example usage
current_code_context = "const [count, setCount] = useState(0);"
query = "How to update state based on previous state in React?"
combined_query = f"Context: {current_code_context}\nQuery: {query}"
retrieved_results = retrieve_from_chromadb(combined_query)
# Process results
if retrieved_results and retrieved_results['documents']:
print(f"Retrieved {len(retrieved_results['documents'][0])} relevant chunks:")
for i, doc in enumerate(retrieved_results['documents'][0]):
distance = retrieved_results['distances'][0][i]
metadata = retrieved_results['metadatas'][0][i]
print(f" - Chunk {i+1} (Distance: {distance:.4f}, Source: {metadata.get('source', 'N/A')}):")
print(f" {doc[:100]}...") # Print first 100 chars
IDE Use Case: Building a Custom Documentation Assistant
Imagine your team uses a proprietary internal framework with extensive documentation. By turning this documentation into vector knowledge, you can build a custom coding assistant right within your IDE (e.g., VS Code with Roo Code) that provides hyper-relevant suggestions.
Scenario
A developer is using your internal UI component library and needs to implement a complex data grid with custom sorting and filtering.
Implementation Steps
- Scrape and Process: Set up a pipeline to scrape your internal framework’s documentation (e.g., from Confluence, Git repositories, or a dedicated docs site).
- Embed and Store: Generate embeddings for the documentation chunks and store them in a dedicated Chroma DB collection (e.g.,
internal_framework_docs). - Integrate with IDE Extension: Modify your Roo Code extension or build a new one that:
- Detects when the developer is working with the internal framework.
- Captures the current code context and developer intent.
- Queries the
internal_framework_docscollection in Chroma DB. - Sends the code context and retrieved documentation to an AI model via an MCP server.
- Displays the AI-generated suggestions, citing the internal documentation sources.
Example Interaction
Developer types:
import { DataGrid } from '@my-company/ui-lib';
// Need to implement custom server-side sorting for the DataGrid
The custom assistant, powered by vector knowledge of your internal docs, suggests:
// Roo Code Suggestion (powered by internal docs):
import { DataGrid, useServerSideFeatures } from '@my-company/ui-lib';
function MyCustomGrid() {
const { sortModel, handleSortModelChange } = useServerSideFeatures({
initialSortModel: [{ field: 'createdAt', sort: 'desc' }],
fetchDataFunction: async (sortOptions) => {
// Call your API endpoint with sorting parameters
const response = await fetch(`/api/data?sortField=${sortOptions.field}&sortOrder=${sortOptions.sort}`);
return await response.json();
}
});
return (
<DataGrid
columns={/* ... your columns ... */}
rows={/* ... data from fetchDataFunction ... */}
sortingMode="server"
sortModel={sortModel}
onSortModelChange={handleSortModelChange}
// See internal docs: /ui-lib/datagrid/server-side-sorting
/>
);
}
This suggestion is highly specific to the internal library, accurate according to its documentation, and includes a direct reference for further reading—something impossible for generic AI models.
Leverage Your Existing Documentation for AI Power
Your organization’s documentation—whether for internal tools, public APIs, or coding standards—is a valuable asset waiting to be unlocked. By transforming it into intelligent vector knowledge, you can:
- Boost Developer Productivity: Provide instant, relevant answers within the IDE.
- Improve Code Quality: Ensure consistent use of APIs and best practices.
- Accelerate Onboarding: Help new developers quickly learn internal tools and standards.
- Democratize Knowledge: Make specialized information readily available to everyone.
- Create Unique AI Assistants: Build coding tools tailored to your specific technology stack.
ROI: Quantifying the Value of Documentation Vectors
Investing in turning documentation into vector knowledge delivers tangible returns:
- Reduced Documentation Search Time: Developers save an average of 30-60 minutes per day previously spent searching for documentation.
- Fewer API Misuse Errors: Teams report a 40-60% reduction in bugs related to incorrect API usage.
- Faster Feature Implementation: Projects using documentation-aware AI assistants see a 15-25% acceleration in feature delivery.
- Improved Code Consistency: Automated enforcement of standards leads to more maintainable codebases.
Build Your Custom Documentation-Powered Coding Assistant
Imagine an AI coding assistant that perfectly understands your proprietary frameworks, internal APIs, and company-specific coding standards. This isn’t science fiction—it’s achievable today by leveraging your existing documentation.
At YourCompany, we specialize in building custom AI solutions that transform your documentation into powerful vector knowledge. Our services include:
- Documentation Scraping Pipelines: Automated systems to gather and process your documentation from any source.
- Vector Database Implementation: Setting up and optimizing Chroma DB or other vector stores for your needs.
- Custom RAG Systems: Building tailored retrieval systems that understand your specific domain.
- IDE Integration: Creating custom coding assistants for VS Code, Cursor, or other IDEs.
Want a custom documentation-powered coding assistant for your proprietary framework or internal APIs? Contact us today to discuss your requirements!
REQUEST A FREE CONSULTATION LEARN MORE ABOUT OUR CUSTOM AI SOLUTIONS