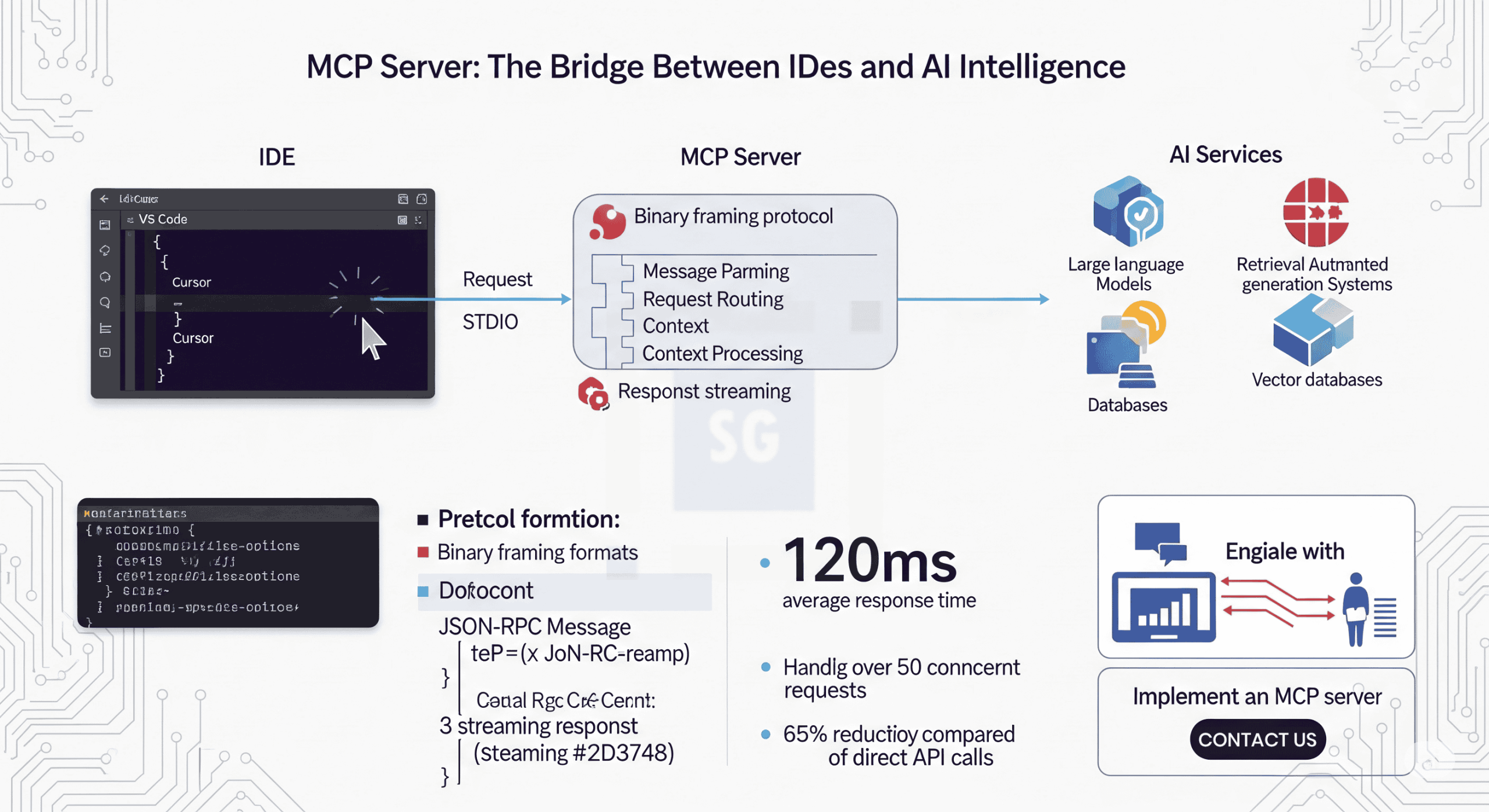




In the rapidly evolving landscape of AI-powered development tools, there’s a critical component that often goes unnoticed but plays a pivotal role in delivering intelligent coding assistance: the Model Control Protocol (MCP) server. This behind-the-scenes technology is the essential bridge that connects your IDE to powerful AI models, enabling seamless integration of advanced code generation, completion, and assistance features.
While developers experience the magic of AI suggestions appearing in their editor, few understand the sophisticated architecture that makes this possible. In this deep dive, we’ll explore how MCP servers work, why they’re crucial for modern development environments, and how proper implementation can dramatically enhance developer productivity.
What is an MCP Server?
An MCP (Model Control Protocol) server acts as an intermediary between your IDE (like Cursor or VS Code with Roo Code) and AI services (such as large language models or RAG systems). It handles the complex communication protocols, context management, and response formatting that enable AI-powered coding assistance to feel natural and integrated.
Think of an MCP server as a specialized translator and coordinator that:
sdsd
-
Receives requests from the IDE with code context and user queries
-
Processes and enriches this context with additional information
-
Communicates with AI models in their required formats
-
Receives and processes AI responses
-
Formats and returns these responses to the IDE in a way it can understand and display

The Critical Role of MCP Servers
MCP servers solve several fundamental challenges in connecting IDEs with AI services:
1. Protocol Translation
IDEs and AI models often speak different “languages.” The MCP server translates between:
-
IDE-specific protocols and formats
-
AI model API requirements
-
Potentially different serialization formats
2. Context Management
AI models have context window limitations. MCP servers:
-
Prioritize the most relevant code context
-
Manage token limits efficiently
-
Ensure critical information is included
3. Response Streaming
Modern AI experiences require real-time feedback. MCP servers:
-
Handle streaming responses from AI models
-
Chunk and forward these responses to the IDE
-
Maintain connection state during long operations
4. Error Handling
When things go wrong, graceful degradation is essential. MCP servers:
-
Catch and process errors from AI services
-
Provide meaningful feedback to users
-
Implement fallback strategies when services are unavailable
The STDIO Protocol: How IDEs Talk to MCP Servers
At the heart of MCP server implementation is the communication protocol between the IDE and the server. Most modern IDE extensions like Cursor and Roo Code use a Standard Input/Output (STDIO) protocol with binary framing for this communication.
Why STDIO?
STDIO offers several advantages for IDE-to-MCP communication:
-
Universal Availability: Available on all operating systems
-
Process Integration: Natural fit for child processes launched by IDE extensions
-
Efficiency: Low overhead compared to network protocols
-
Security: Doesn’t require opening network ports
Binary Framing Explained
Since STDIO provides continuous streams without inherent message boundaries, a framing mechanism is needed to delimit individual messages. This is where binary framing comes in:
Content-Length: 352\r\n
Content-Type: application/json; charset=utf-8\r\n
\r\n
{
"jsonrpc": "2.0",
"id": "request-123",
"method": "generateCode",
"params": {
"context": {
"document": "def process_data(input_data):\n # Need to implement data validation\n pass",
"language": "python",
"position": {"line": 1, "character": 4}
},
"query": "Add input validation for non-empty list of dictionaries"
}
} This approach uses:
-
A header specifying the content length in bytes
-
A content type declaration
-
A blank line separator
-
The actual JSON message content
The receiving end reads the headers, determines the message length, then reads exactly that many bytes to get the complete message.
Message Structure
Within this framing, messages typically follow a JSON-RPC inspired structure:
Request Messages (IDE to MCP Server)
{
"jsonrpc": "2.0",
"id": "request-123",
"method": "generateCode",
"params": {
"context": {
"document": "...",
"language": "python",
"position": {"line": 10, "character": 15}
},
"query": "User's request or instruction"
}
}Response Messages (MCP Server to IDE)
{ "jsonrpc": "2.0", "id": "request-123", "result": { "content": "Generated code or response", "explanation": "Optional explanation", "references": [ {"source": "Documentation", "url": "https://example.com/docs"} ] } } Streaming Response Messages
For real-time feedback, streaming responses use a similar structure with additional fields:
{
"jsonrpc": "2.0",
"id": "request-123",
"partial": true,
"chunk": 1,
"result": {
"content": "Partial content..."
}
} Technical Walkthrough: MCP Server Communication with Cursor
To illustrate how this works in practice, let’s walk through a typical interaction between Cursor (an AI-enhanced IDE) and an MCP server:
1. Initialization
When Cursor launches, it:
-
Starts the MCP server as a child process
-
Establishes STDIO communication channels
-
Performs initial handshake to verify protocol compatibility
2. User Requests Code Completion
When a user triggers code completion:
-
Cursor gathers context:
-
Current file content
-
Cursor position
-
Open files
-
Project structure information
-
-
Cursor sends a request:
-
Formats the context and request as JSON
-
Adds appropriate headers
-
Writes to the MCP server’s standard input
-
Frequently Asked Questions
The Model Context Protocol (MCP) acts as the bridge between IDEs (like VS Code or Cursor) and AI services. It formats and transmits code context and user requests to large language models and handles the structured responses, enabling real-time coding assistance.
STDIO communication uses standard input/output streams to send and receive data between the IDE and the MCP server. It uses headers like Content-Length to define message size and binary framing to delimit each message accurately.
The Content-Length header tells the receiving side how many bytes to read for the current message. It's essential for proper message framing in STDIO, ensuring the server reads complete messages without mixing them up.
JSON-RPC is a lightweight remote procedure call protocol. MCP servers often use JSON-RPC–like structures to define method calls (generateCode, getContext) and responses, making the protocol easily extensible and structured.
Since STDIO is a continuous byte stream, binary framing introduces boundaries between messages using headers. This prevents incomplete or overlapping messages when multiple requests are in flight.
Yes. Modern MCP servers are built to handle streaming responses from AI models, enabling partial suggestions to appear in real-time as you type, enhancing responsiveness and user experience.
While both facilitate communication between editors and services, LSP focuses on static code analysis (linting, autocomplete), whereas MCP is specifically designed for dynamic, AI-driven responses from language models.
Calling an LLM API directly from an IDE extension usually leads to scattered, ad-hoc integrations. An MCP server centralizes that logic: it owns context management, retrieval, security, and tool orchestration. The IDE becomes a thin client speaking a standard protocol, while the MCP server can evolve independently (new tools, better context windows, caching, multi-model routing) without shipping a new extension every time.