



In the rapidly evolving landscape of AI-powered development tools, a revolutionary approach has emerged that’s transforming how developers interact with their IDEs: Retrieval-Augmented Generation (RAG). This powerful technique combines the creative capabilities of large language models with the precision of knowledge retrieval systems, creating coding assistants that don’t just generate code—they generate contextually relevant and technically accurate code.
While traditional code completion tools rely solely on pattern recognition from their training data, RAG-powered systems can access, retrieve, and leverage up-to-date documentation, library references, and best practices in real-time. The result? A quantum leap in the quality and relevance of AI coding assistance.
Understanding RAG: The Perfect Marriage of Knowledge and Generation
At its core, RAG combines two powerful capabilities:
- Retrieval: The ability to search through and identify relevant information from a knowledge base
- Generation: The ability to create new, coherent content based on context and instructions
In a RAG system for code assistance, when a developer starts typing or requests help, the system doesn’t just predict the next tokens based on patterns it learned during training. Instead, it:
- Analyzes the current code context and developer intent
- Retrieves relevant documentation, examples, and references from its knowledge base
- Uses this retrieved information to inform and enhance its code generation
- Produces suggestions that are both contextually appropriate and technically accurate
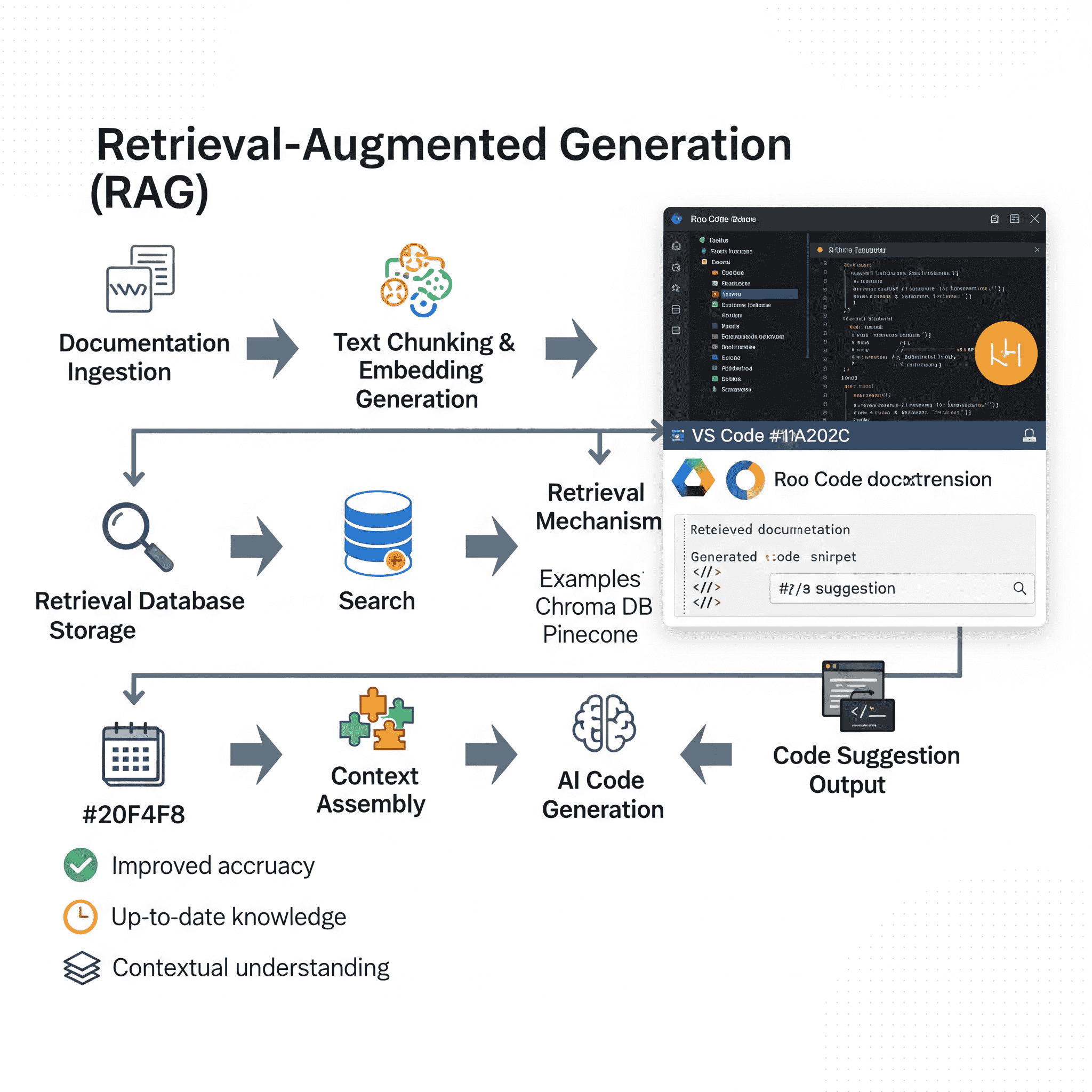
The RAG Architecture Explained
A typical RAG system for code assistance consists of several key components:
1. Vector Database
At the heart of any RAG system is a vector database that stores documentation, code examples, API references, and best practices as numerical vectors (embeddings) that capture their semantic meaning. Popular vector databases for this purpose include:
- Chroma DB: Optimized for RAG applications with excellent query performance
- Pinecone: Scalable vector database with robust similarity search
- Weaviate: Open-source vector search engine with classification capabilities
- FAISS: Facebook AI’s efficient similarity search library
These databases allow for lightning-fast retrieval of relevant information based on semantic similarity rather than just keyword matching.
2. Embedding Models
To convert documentation and code into vector representations, RAG systems use embedding models specifically tuned for code understanding. These models transform text and code into high-dimensional vectors that capture their semantic meaning and technical relationships.
Popular embedding models for code include:
- CodeBERT: Specifically pre-trained on programming languages
- OpenAI’s text-embedding-ada-002: General-purpose embedding model with good code understanding
- Sentence-Transformers: Customizable models that can be fine-tuned for code embedding
3. Retrieval Mechanism
When a developer requests assistance, the RAG system employs sophisticated retrieval mechanisms to find the most relevant information:
- Semantic Search: Finding documentation and examples that are conceptually related to the current code context
- Hybrid Search: Combining keyword-based and semantic approaches for better precision
- Re-ranking: Applying additional filters to prioritize the most relevant results
- Contextual Filtering: Considering the programming language, libraries in use, and project-specific patterns
4. Generation Component
The final piece is a large language model (LLM) that takes both the developer’s context and the retrieved information to generate helpful suggestions:
- Context Assembly: Combining the developer’s code, their query, and the retrieved documentation
- Prompt Engineering: Crafting effective instructions that guide the LLM to produce useful code
- Response Generation: Creating code suggestions, explanations, or recommendations
- Citation: Linking generated code back to the source documentation when appropriate
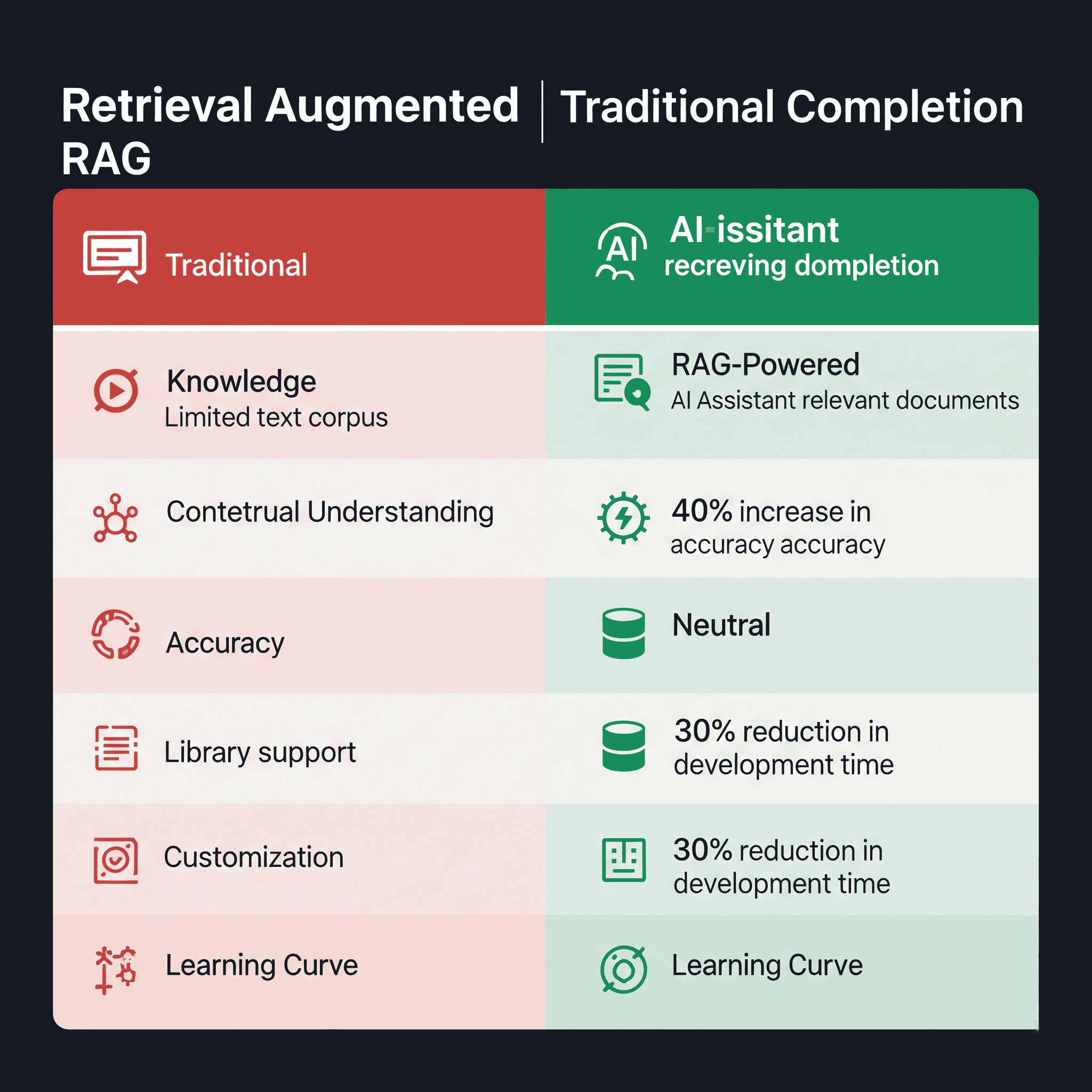
RAG vs. Traditional Code Completion: A World of Difference
To understand the transformative impact of RAG, let’s compare it with traditional code completion approaches:
| Aspect | Traditional Code Completion | RAG-Powered Assistance |
|---|---|---|
| Knowledge Source | Limited to training data (often outdated) | Up-to-date documentation and references |
| Contextual Understanding | Based on immediate code context | Incorporates broader project and documentation context |
| Accuracy | May hallucinate or suggest deprecated approaches | Grounded in actual documentation and best practices |
| Library Support | Limited to popular libraries in training data | Can access documentation for any library in the knowledge base |
| Customization | Generic suggestions for all users | Can be tailored with organization-specific documentation |
| Learning Curve | Requires developers to verify suggestions | Provides references to help developers understand suggestions |
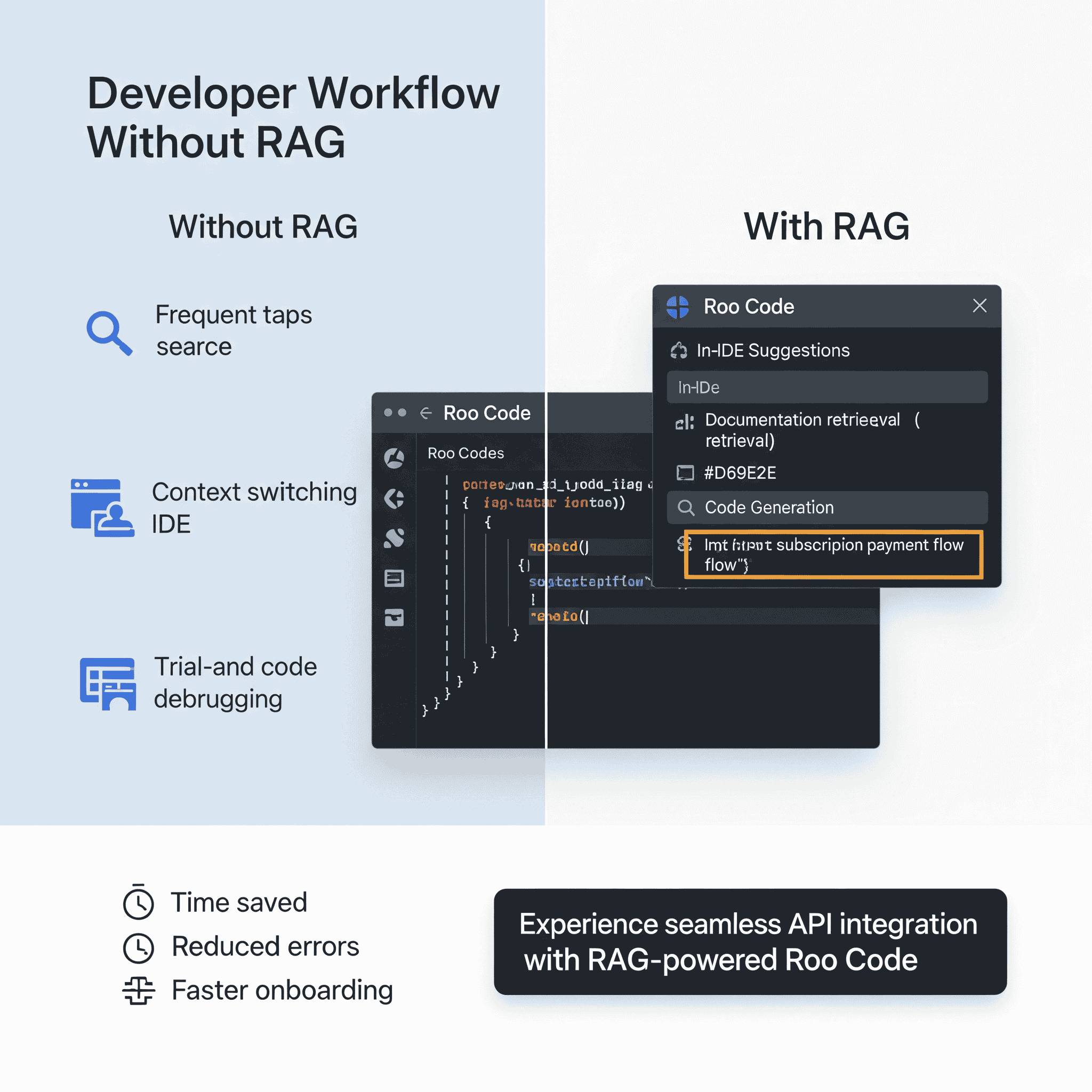
Real-World Example: RAG in VS Code with Roo Code
To illustrate the power of RAG in action, let’s look at how it transforms the development experience in VS Code with the Roo Code extension.
Scenario: Working with a Complex API
Imagine a developer working on an application that needs to integrate with the Stripe payment API. They’ve added the library but aren’t familiar with how to implement a subscription payment flow.
Without RAG:
The developer would need to:
- Switch to a browser
- Search for Stripe documentation
- Find the subscription API section
- Read through examples
- Switch back to VS Code
- Try to implement the solution from memory
- Repeat when encountering issues
With RAG-Powered Roo Code:
The developer simply types a comment or starts implementing:
// Create a subscription for the customer with monthly billing
// Roo Code suggests:
const subscription = await stripe.subscriptions.create({
customer: customerId,
items: [{ price: 'price_monthly_standard' }],
payment_behavior: 'default_incomplete',
payment_settings: { save_default_payment_method: 'on_subscription' },
expand: ['latest_invoice.payment_intent'],
});
// Handle the subscription status
if (subscription.status === 'active') {
// Subscription is active, provision access
return { success: true, subscriptionId: subscription.id };
} else if (subscription.status === 'incomplete') {
// Subscription requires additional action
return {
success: false,
clientSecret: subscription.latest_invoice.payment_intent.client_secret
};
}The suggestion comes with:
- A reference to the exact Stripe documentation section
- Notes about best practices for handling subscription statuses
- Explanations of key parameters
- Links to related documentation for error handling
This is possible because the RAG system:
- Recognized the intent to create a Stripe subscription
- Retrieved the latest Stripe API documentation on subscriptions
- Identified best practices for subscription creation and status handling
- Generated code that follows these practices and includes proper error handling
- Provided references to the source documentation
The Technical Magic Behind RAG for Code
Let’s dive deeper into how RAG systems for code assistance actually work:
1. Documentation Ingestion and Embedding
Before a RAG system can retrieve relevant information, it needs to process and store documentation:
# Example of documentation ingestion pipeline
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
# Load documentation from various sources
stripe_docs = WebBaseLoader("https://stripe.com/docs/api").load()
react_docs = WebBaseLoader("https://reactjs.org/docs").load()
# Split into manageable chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(stripe_docs + react_docs)
# Create embeddings and store in vector database
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents=all_splits, embedding=embeddings) 2. Context-Aware Retrieval
When a developer needs assistance, the system analyzes their current context and queries the vector database:
# Example of retrieval process
def retrieve_relevant_docs(code_context, user_query, vectorstore):
# Combine code context and user query
combined_query = f"Code context: {code_context}\nUser query: {user_query}"
# Retrieve relevant documentation
docs = vectorstore.similarity_search(combined_query, k=5)
# Rerank results based on relevance to code context
reranked_docs = rerank_by_relevance(docs, code_context)
return reranked_docs 3. Enhanced Generation with Retrieved Context
Finally, the system uses the retrieved information to generate helpful suggestions:
# Example of generation with retrieved context
def generate_code_suggestion(code_context, user_query, retrieved_docs, llm):
# Format retrieved documentation
formatted_docs = "\n\n".join([f"Documentation: {doc.page_content}\nSource: {doc.metadata['source']}"
for doc in retrieved_docs])
# Create prompt with context and retrieved information
prompt = f"""
You are an expert coding assistant. Based on the following context and retrieved documentation,
generate the appropriate code to help the user.
User's code context: ```
{code_context} ```
User's query: {user_query}
Relevant documentation: {formatted_docs}
Generate the code solution: """
# Generate response response = llm.generate(prompt)
return response This approach ensures that the generated code is grounded in actual documentation rather than the model’s potentially outdated or incorrect knowledge.
Implementing RAG in Your Development Environment
The benefits of RAG for code assistance are clear, but how can organizations implement this technology in their own development environments?
1. Choose Your Vector Database
Select a vector database that meets your performance and scaling requirements:
- Chroma DB: Excellent for teams getting started with RAG
- Pinecone: Good for larger organizations with substantial documentation
- Weaviate: Ideal when classification and schema features are needed
- FAISS: Best for teams with ML expertise who need customization
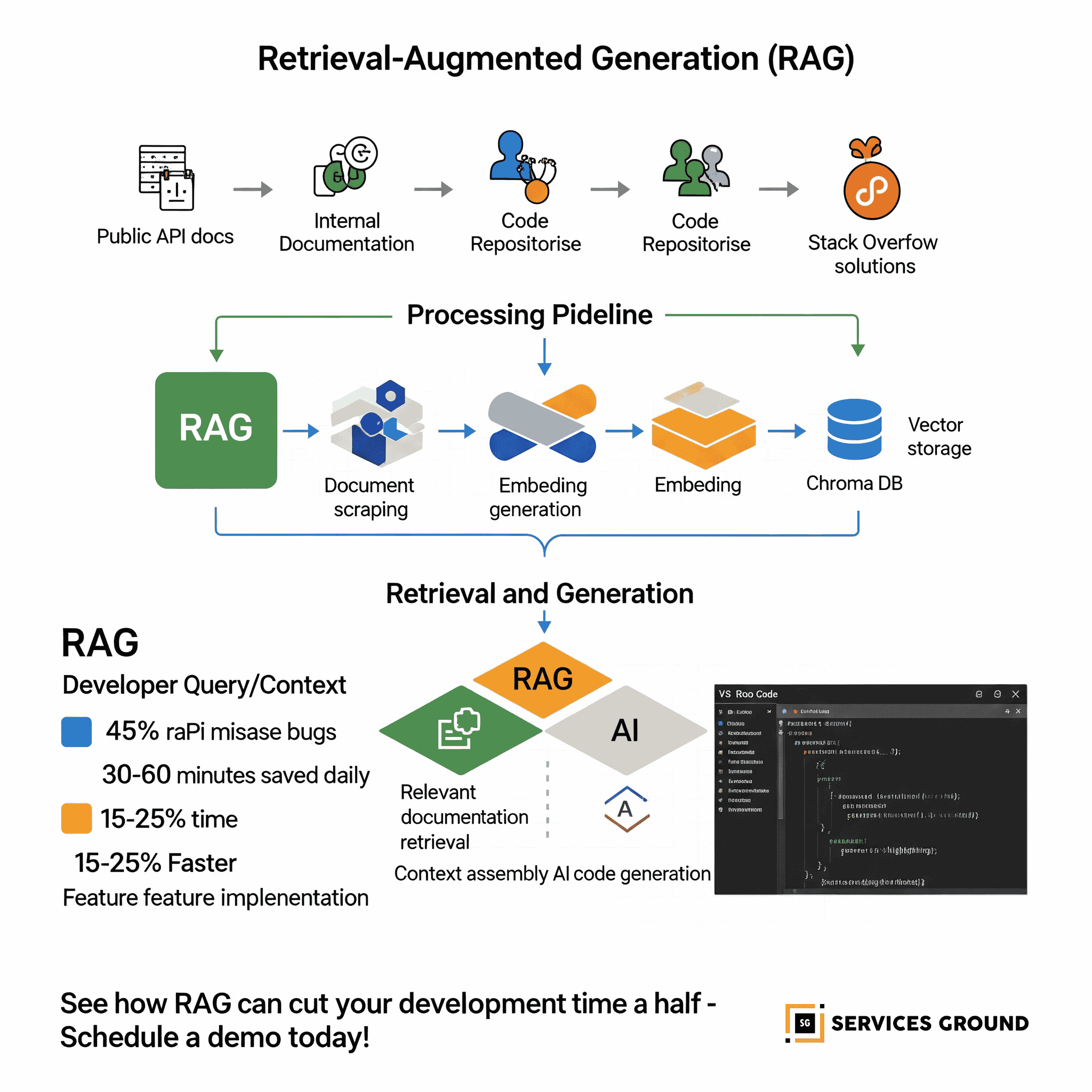
2. Prepare Your Documentation Sources
Identify and prepare the documentation sources most relevant to your development:
- Public library and framework documentation
- Internal API documentation
- Company coding standards and best practices
- Example code repositories
- Stack Overflow solutions and discussions
3. Set Up the Embedding Pipeline
Create a pipeline to regularly update your knowledge base:
- Scrape and process documentation
- Generate embeddings
- Update the vector database
- Version control your knowledge base
4. Integrate with Your IDE
Choose an integration approach:
- Use existing RAG-powered extensions like Roo Code
- Develop custom extensions for your specific needs
- Implement an MCP (Model Control Protocol) server that connects your IDE to your RAG system
5. Train Your Team
Help your development team get the most from RAG-powered assistance:
- Provide guidelines on how to effectively query the system
- Establish practices for validating and reviewing AI-generated code
- Create feedback loops to continuously improve the system
ROI: The Business Case for RAG-Powered Development
Implementing RAG for code assistance isn’t just technically impressive—it delivers measurable business value:
1. Development Speed
Teams using RAG-powered coding assistants report:
- 30-50% reduction in time spent on API integration tasks
- 25-40% faster implementation of standard patterns
- 20-35% reduction in time spent consulting documentation
2. Code Quality
RAG systems help improve code quality by:
- Reducing bugs related to API misuse by up to 45%
- Ensuring consistent implementation of best practices
- Decreasing technical debt from outdated patterns
3. Developer Onboarding
Organizations see significant improvements in onboarding:
- New developers reach productivity 40% faster
- Reduced dependency on senior developers for guidance
- More consistent code quality across experience levels
4. Knowledge Democratization
RAG systems democratize access to knowledge:
- All developers have equal access to best practices
- Specialized knowledge becomes available to the entire team
- Reduced “knowledge silos” and bus factor
Stop Reinventing the Wheel – Let RAG Find the Right Code Patterns for You
In today’s competitive landscape, development efficiency is a critical advantage. RAG-powered code assistance represents a step-change in how developers interact with documentation and implement solutions.
By combining the creative power of large language models with the precision of knowledge retrieval, RAG systems ensure that your developers always have access to the most relevant, up-to-date information exactly when they need it—right in their IDE.
At Services Ground, we specialize in implementing custom RAG solutions for development teams. Our experts can help you:
- Build a comprehensive knowledge base from your documentation
- Implement efficient retrieval systems optimized for your codebase
- Integrate RAG capabilities with your existing development tools
- Train your team to maximize the benefits of RAG-powered assistance
Want to see how RAG can cut your development time in half? Schedule a demo with our experts!